bunkoOCRのWindows版のページです。
20250311版以降からアップデートする方は、exeだけでいいのでこちらのファイルをお使いください。 https://lithium03.info/archives/bunkoOCR/bunkoOCR_20250314_patch.zip
float16速度テスト https://lithium03.info/archives/bunkoOCR/bunkoOCR_20250314b_patch.zip
上手く実行できないときは、ランタイムを入れると動きます。 https://aka.ms/vs/17/release/vc_redist.x64.exe
実行がDefenderにブロックされることがあります。exeをそれぞれ一回ダブルクリックして、警告画面を出してから実行するを選んでフラグをクリアすると動きます。
bunkoOCR_20230917に、元ファイルを誤って上書きするバグがあります。使用した方は、元ファイルを確認お願いします。
findtextCenterNet https://github.com/lithium0003/findtextCenterNet で公開している機械学習モデルを、アプリとして使えるようにしたbunkoOCRのWindows版です。 このプログラムは、画像からOCR(光学文字認識)を行い、テキストに変換します。 新しめのGPUがあると、非常に高速に実行できます。
Windowsで動作します。iOS/macOSで利用したい場合は、こちらのページにあるリンクより AppleStoreからダウンロードしてください。

ダウンロードリンクから、zipファイルをダウンロードし、任意の場所に展開してください。 bin/bunkoOCR.exeを実行します。(OCRengine.exeは内部用です)
Add fileボタンを押し、ファイルを選びます。もしくは、フォームに画像ファイルをD&Dします。 左側のリストに、待機中のファイルが入ります。 順次処理が始まり、右側のリストに移ったら終了です。
先にリストに追加して、後から処理をまとめて行いたい場合は、設定画面から自動開始をOFFにすることで、 Startボタンが押せるようになり、押したタイミングで処理がスタートします。
右側のリストでファイルを選んで、Show resultボタンを押すと 結果が表示されます。
image.pngを処理した場合
GPUで処理する場合、初回実行時にキャッシュが生成されるので 非常に時間がかかります。(GPUやPCの状況によっては10分程度かかる場合もあります) 2枚目以降の画像は高速に処理されます。 cacheフォルダを消さない限り、次回以降は高速に処理されます。
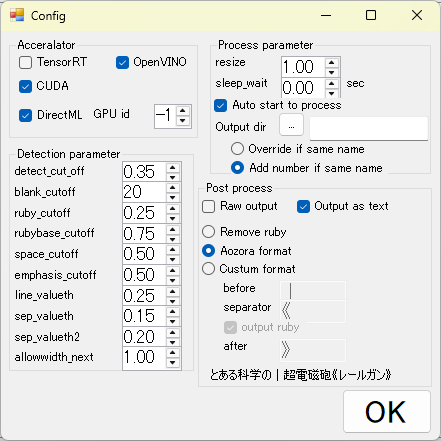
NVIDIAのGPUでTensorRTを選ぶと最も速くなりますが、初回の前処理に一番時間がかかります。 GPUを使いたくない場合は、設定画面からTensorRT, CUDA, DirectMLをチェックを外します。 Intel CPUの場合は、OpenVINOが若干速いので使うとよいと思われます。 どれにもチェックいれなくてもCPUでまあまあの速度で走る様に調整しました。
2023/09/09 初版
2023/09/10 裏写り除去ルーチンを入れ忘れていたので修正
2023/09/10b 裏写り除去ルーチンと、文のライン検出のパラメータを修正
2023/09/11
検出パラメータを調整できるように修正
画像のExifに回転情報が入っている場合におかしくなるのを修正
2023/09/14
日本語のファイル名が入ると処理に失敗することがあるのを修正
何も文字がない画像を与えると落ちるのを修正
NvidiaのGPUがない場合に、DirectMLで処理するように修正
2023/09/15
日本語のファイル名が入ると処理結果が虚空に消えるのを修正
複数のGPUがある場合にDirectMLでよさそうなものを選択するように
2023/09/17 一度に沢山のファイルを追加した際に固まるのを修正
2023/09/17b GPUの判定を分離して、失敗した場合はCPUモードで処理するように修正
2023/09/18 GPUを使わないように強制するオプションを追加
パラメータが保存されているparam.configをテキストエディタで開き、
use_GPU:0に書き換えるとDirectMLを使用しないように強制できます。
(現バージョンでは設定から使用するGPUエンジンを選択できるようになりました)
2025/03/11 機械学習モデルを新しくしたので、色々と変更
2025/03/13 UIを修正。出力先を指定出来るように
2025/03/14 スレッド競合で、リストがちゃんとクリアされないバグを修正
処理待ちリストには、同じファイルが2回以上追加できないようにしました。
処理が終了していれば、もう一度追加することが可能です。
作者に、認識に不具合のある画像データを送りたい場合は、https://lithium03.info/upload/ からサーバーに送付することができます。