
機械学習による光学文字認識(OCR)を行い、文字起こしするソフトです。 端末内ですべて計算されるため、外部へのデータの送信は一切ありません。 ふりがなが付いている文庫本を見開きで撮影して、認識させることができます。
このアプリは、アプリ内課金メニューが設定されていますが、全ての機能が無料で使用できます。 課金メニューは、作者への寄附とお考えください。 購入した場合、シークレット画像が解放されます。 機械学習モデルの作成にGPUを長期間使用する必要があるため、より精度の高いモデルに改良するために支援を募集中です。
使用している機械学習モデルのソースコードは、 https://github.com/lithium0003/findtextCenterNet にあります。
Windows版はこちら
プライバシーポリシーはこちらで確認できます。 このアプリによるデータの送信はありません。
このアプリによってOCR処理したサンプルです。




撮影に使用した文庫本は、江戸川乱歩傑作選(新潮文庫) / 著:江戸川乱歩 より「二銭銅貨」
トップメニューから、カメラで撮影するか画像データを選んでOCR処理を行います。画像は複数枚同時に選択できます。

トップメニューから、「カメラ撮影」を選択して、カメラを起動します。 プレビュー画面のピントを合わせたい場所をタップして、ピントを合わせます。 レンズが複数ある場合は、切り替えることが可能です。

カメラで撮影した後に撮影画面を閉じるか、画像を選択した後には、自動でOCR結果画面に切り替わり、進捗状況が表示されます。 初回起動時は、機械学習モデルの前処理が行われるので少し時間がかかります。 各項目のプログレスバーが100%になりDoneとなると終了です。 カメラで撮影した画像サイズで、平均的な文庫本の見開きの文字数で、デバイスの性能にもよりますが1枚30秒程度かかります。 処理時間は、画面サイズと、写っている文字数に比例して長くなります。
撮影、または画像選択ごとに、1枚目の縮小画像をサムネイルとして、デフォルトで処理開始時間を名前としています。 各行をタップすると、処理結果が表示されます。


各行で、左スワイプすると削除メニューが出ます。 右スワイプすると、再解析メニューと、名前の編集メニューが出ます。
認識結果を見ながら、設定を微調整したい場合は、再解析メニューから同じ画像に対して再度処理を行うと便利です。
OCR結果画面で、見たい結果をタップすると認識結果画面に切り替わり、認識文字列が表示されます。


上部にあるアイコンから、いくつか操作して見やすくできます。
 | 複数枚ある場合に、次の画像へ切り替え 長押しでページ選択ウインドウ |
 | 改行を除去する |
 | テキストをエクスポートする |
 | 詳細な認識結果画像を表示 |
 | 文字サイズを変更 長押しで初期サイズにリセット |
 | 縦書きと横書きの切り替え |
 | 認識結果を読み上げ |
認識結果画面から、上部のアイコンをタップすると、見ることができます。


右上のボタンから、オリジナル表示と、認識結果のオーバーレイ表示を切り替えて表示できます。 押すたびに、オリジナル→文字認識Box→認識文字列の行→認識文字列のブロック、の順に切り替わります。
認識した文字の、認識boxと1文字ずつの認識文字や、文字の順番の連番が振られています。青線で示されているのは、文字列の認識ラインで、 緑色で示されているのは、段組の間や罫線で文章が切れるところのラインです。また、ふりがなはピンク色、ふりがなの親文字はシアン色でBoxが囲われています。 英文の単語区切りの空白や、行頭の字下げ等の空白の次の文字は、赤色でBoxが囲われています。

認識した行を表示した画面では、各行が囲まれた状態で表示されます。変なところで切断されていたり、逆に段組が繋がってしまっている場合は。 行をトラックする閾値や段組の分割閾値などを、設定画面からパラメータ調整をすると認識が改善される場合があります。

認識したブロックを表示した画面では、段落ブロックごとに各行が連結された結果のブロックが囲まれた状態で表示されます。 本来繋がってほしいところが、行間が広いなどで上手く繋がっていない場合や、逆に狭すぎて2つ隣の行と連結してしまっていたりした場合は、 設定画面から行間のパラメータを調整できます。

認識が上手くいかない場合は、この詳細な認識結果を元にパラメータを調整すると、よい結果が得られることがあります。
OCRした際に、紙面の端で改行されているものも、そのままスキャンして認識されます。これを除去して文を繋げたい場合は、 表示画面の改行除去モードを使用できます。このモードの状態で、エクスポートすると反映された状態でエクスポートできます。


一冊スキャンした場合に、多数のページを切り替えながら表示するのが面倒な場合は、全ページを連結して1画面で表示することができます。

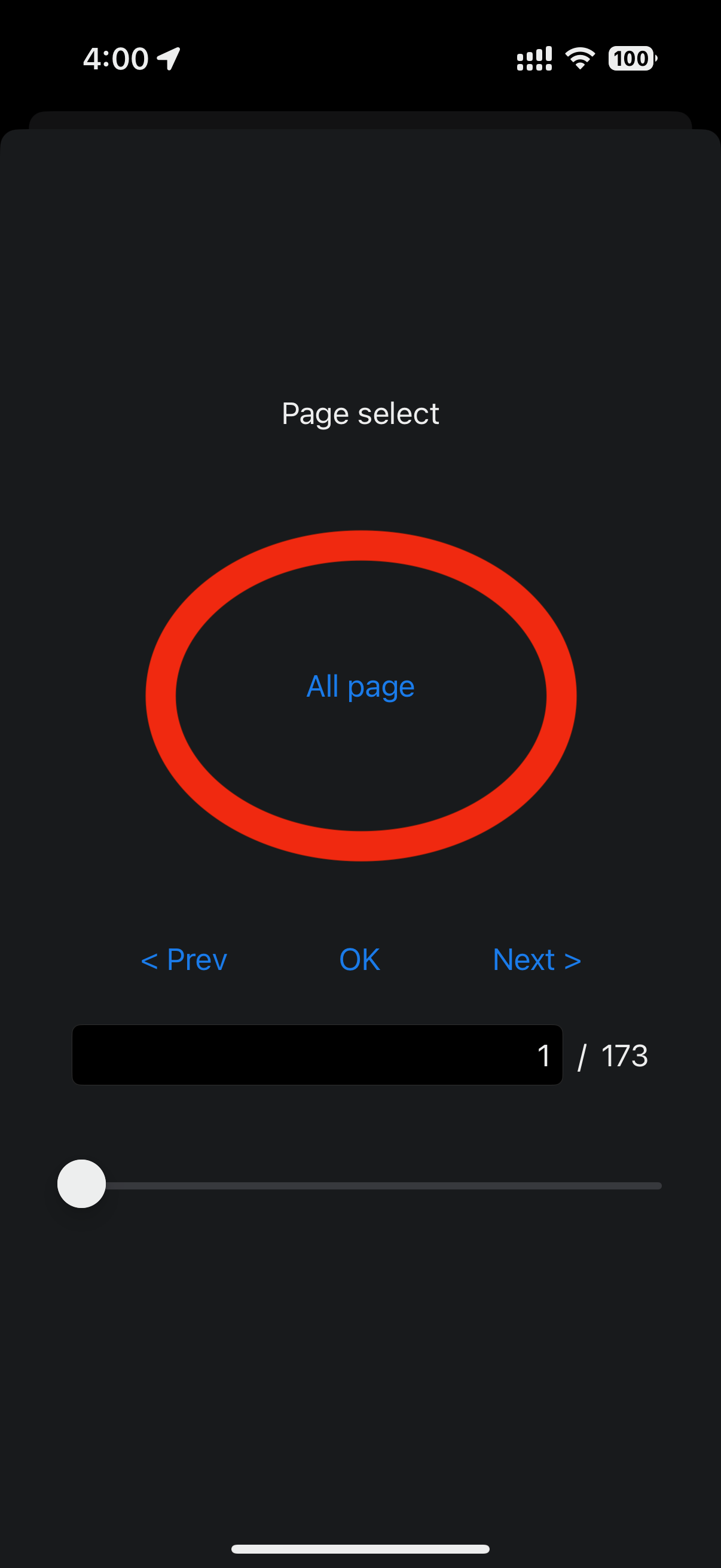
全ページ表示モードで改行を除去すると、ページを跨いで文が連続している部分を連結することができます。 デフォルト状態では、見開きのノドのページまたぎの部分、段組の段の切れ目、撮影のページまたぎの部分に文の切れ目が来た場合には、1行空けたままにします。 これを、文中に明示的に1行空けている部分を残して、全て余分な改行を無くすこともできます。


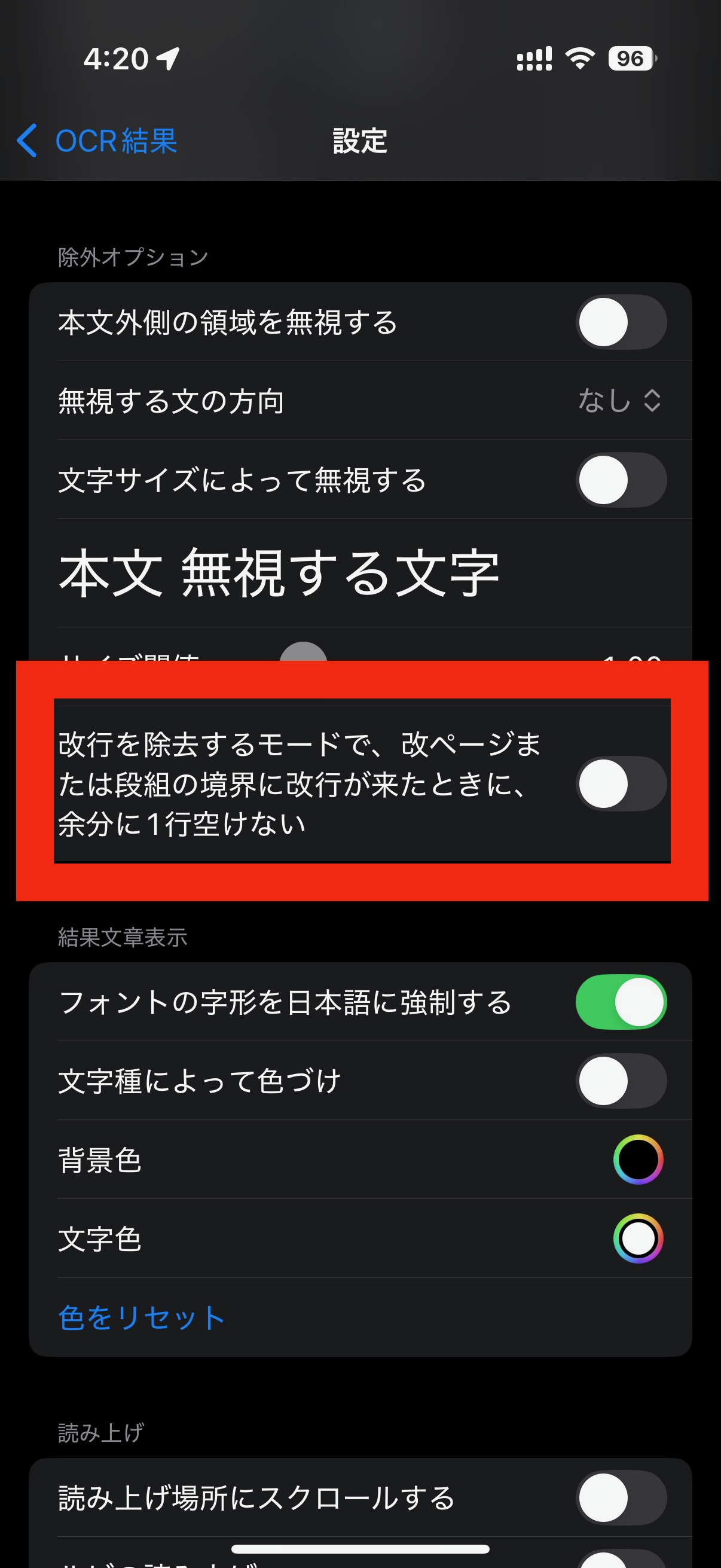
設定画面の除外オプションの中にある、「改行を除去するモードで、改ページまたは段落の境界に改行が来たときに、余分に1行空けない」 オプションをONにすることで、表示が切り替わります。
画面をスクロールすると、右端(横書き)または下端(縦書き)にスクロールインジケーターが表示されます。全体のうちおおよその表示位置を知ることができます。 このスクロールバーは、技術的な問題でぐぐっと持って任意の場所にスクロールさせるUIにするのが大変だったので、 別の方法で長距離スクロールができるようにしてあります。全ページ表示モードなどで、行数が非常に多い場合に便利です。
スクロールインジケーターが表示される付近に、薄い灰色で示してある領域があります。ここを2秒以上ロングタップして押さえたままにして、 そのまま上下に動かすと、任意の割合の場所にジャンプすることができます。
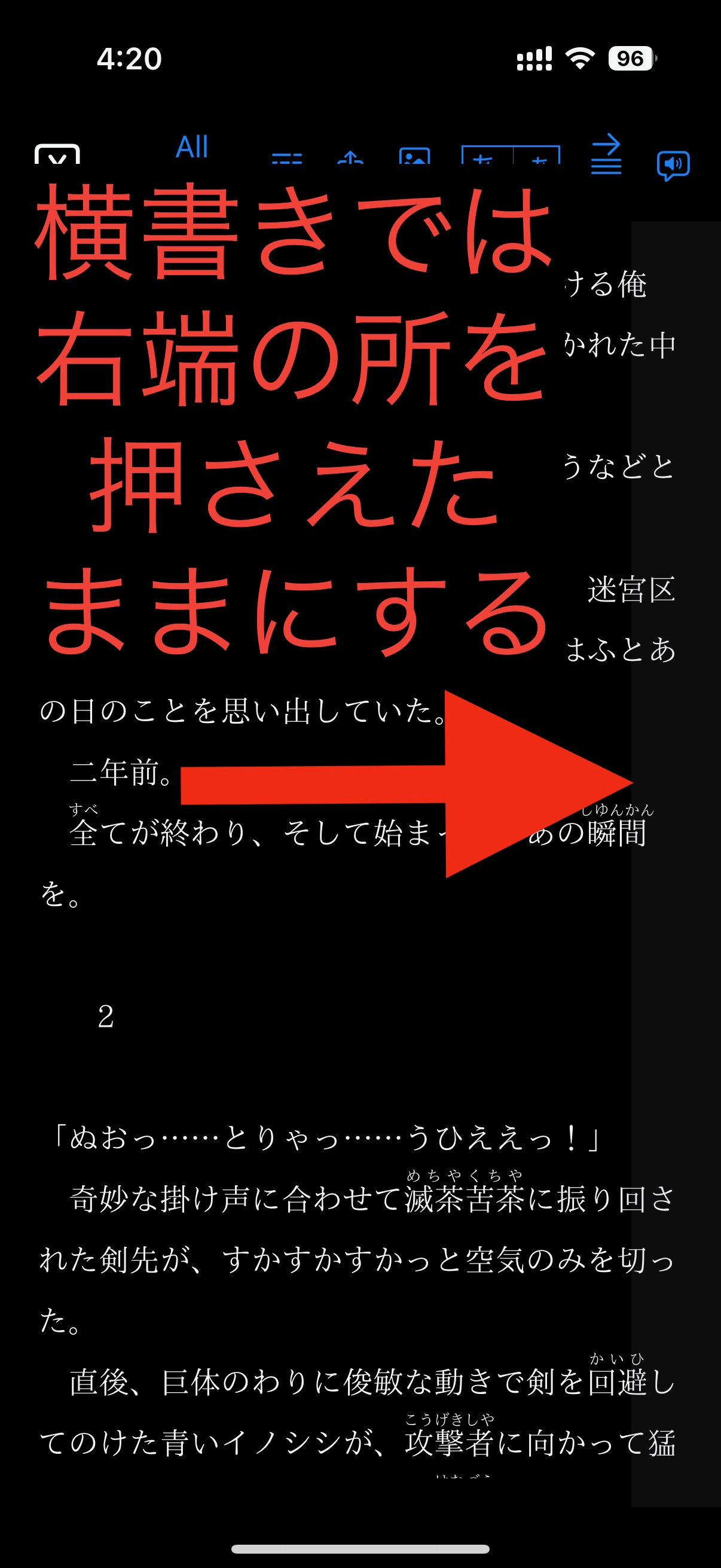

スクロール中に表示を更新するのが技術的に困難だったので、スクロール場所の情報だけが表示され、指を離すと内容が表示更新されるようになっています。 全ページ表示モードでは、スクロール位置のページ番号が表示されますので、参考にしてください。
iOSに装備されている読み上げエンジンを使って、認識内容を読み上げさせることができます。

以前のバージョンでは、最初からしか読み上げできませんでしたが Ver3.2 からは表示している部分の先頭から読み上げをスタートできるようになりました。 全ページ表示モードなどの長文の場合に、任意の場所から読み上げさせることが可能になります。
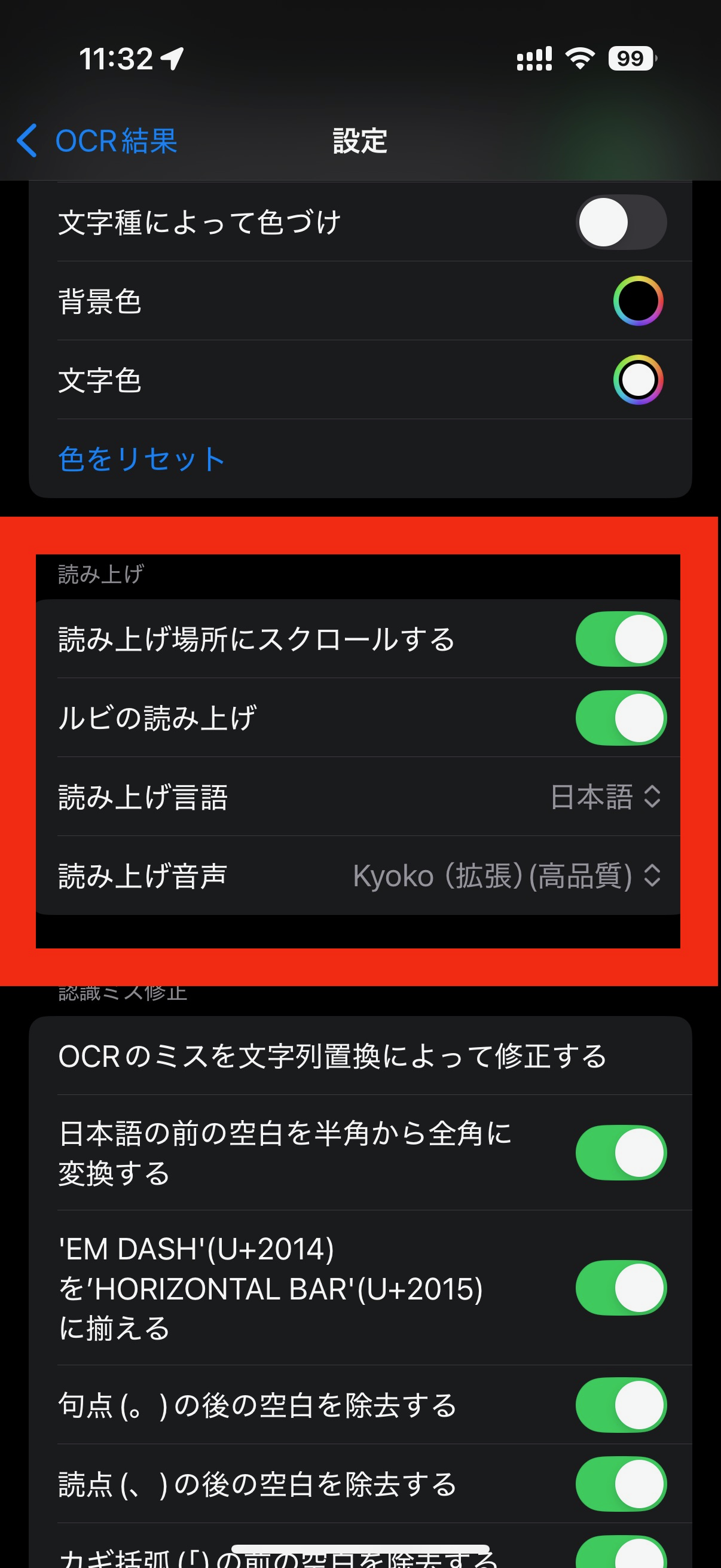
設定画面から、読み上げのオプションを設定できます。 デフォルトでは、読み上げと表示は同期していませんが、「読み上げ場所にスクロールする」を使うと、現在発声している場所にスクロールし続けます。
「ルビの読み上げ」をONにすると、本文の方をエンジン任せの読みにするのではなく、ふりがなを読むようになります。
この場合、現時点では漢字の情報が使用されなくなるので、イントネーションなどがおかしくなるときがあります。
また、"とある科学の
カメラ撮影にはいくつかオプションが用意されています。
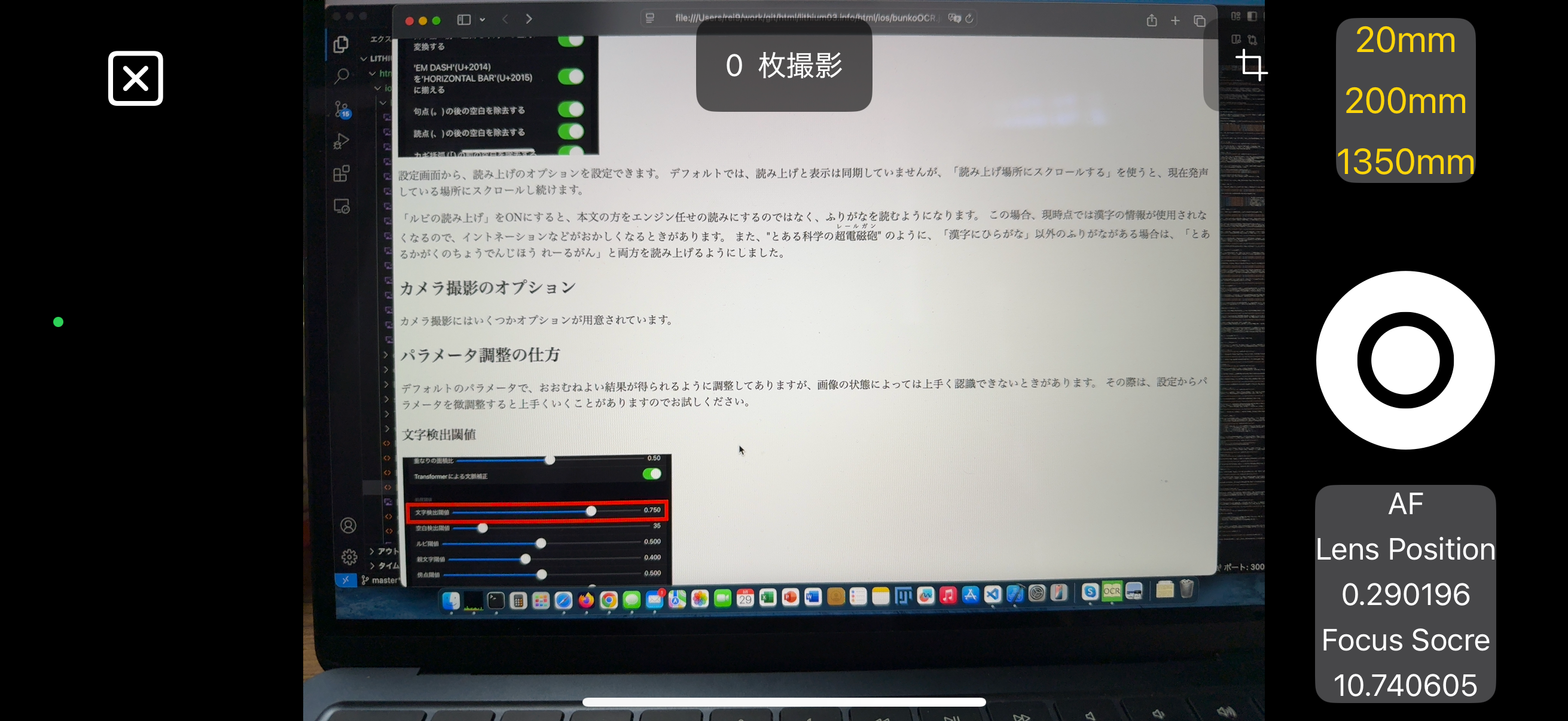
"Lens Position" は、0-1でレンズ位置が示されています。 オートフォーカスで、0より近いとき、1より遠いときは表示が赤くなります。 物理的に動かすか、レンズを切り替えてください。
"Focus Score" は、画像をフーリエ変換して高周波成分があるかどうかをスコアにしています。 ピントが合ってない場合は、ぼやけているので高周波成分が無くなるのでスコアが下がります。 文字がたくさんあって、ピントが合っている場合には、高周波成分が多くなるのでスコアが上がります。 表示は、10以下になると赤く、20以上になると緑になります。
画像の状況によって、"Focus Score" は変動します。特に空白の多いページでは、原理上スコアが下がります。 あくまで、ピントを動かした時に相対的にスコアが上がるか下がるかで、評価するのがよいと思われます。
"Lens Position" などの情報が表示されている領域を、シングルタップするとオートフォーカスに、ダブルタップすると自動調整フォーカスになります。 画面上の任意の場所をタップすることにより、その場所に対してオートフォーカスしてフォーカスを固定します。
"Lens Position" などの情報が表示されている領域を、ダブルタップすると自動調整固定フォーカスになり、シャッターボタンが青くなります。 自動でフォーカスを動かして、"Focus Score" が高くなるように調整します。 調整が終わった後は、固定フォーカスに移行します。
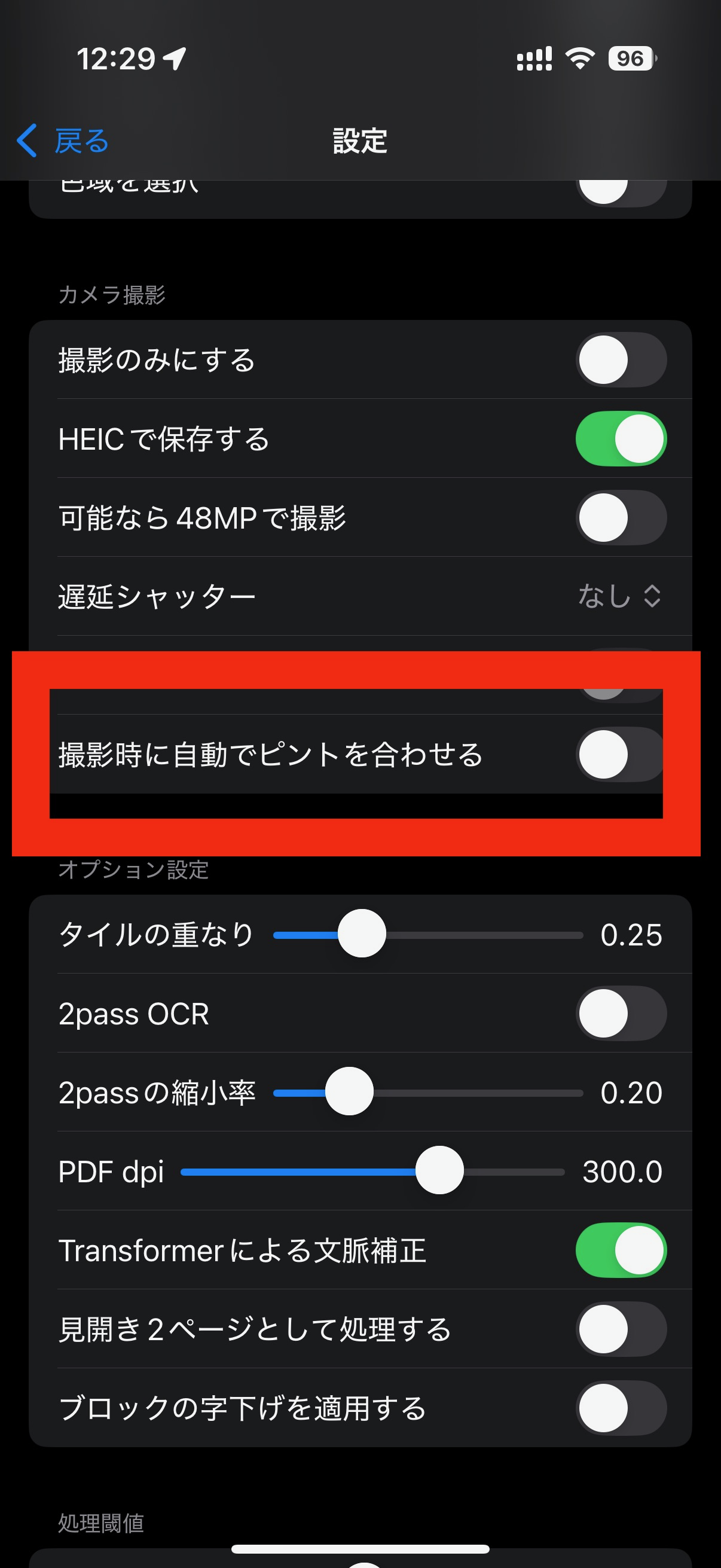
シャッターボタンを押して撮影する度に、この自動調整を毎回行うように設定できます。 カメラを固定して本を連続撮影するときに、ピントを毎回調整したい場合に有用です。
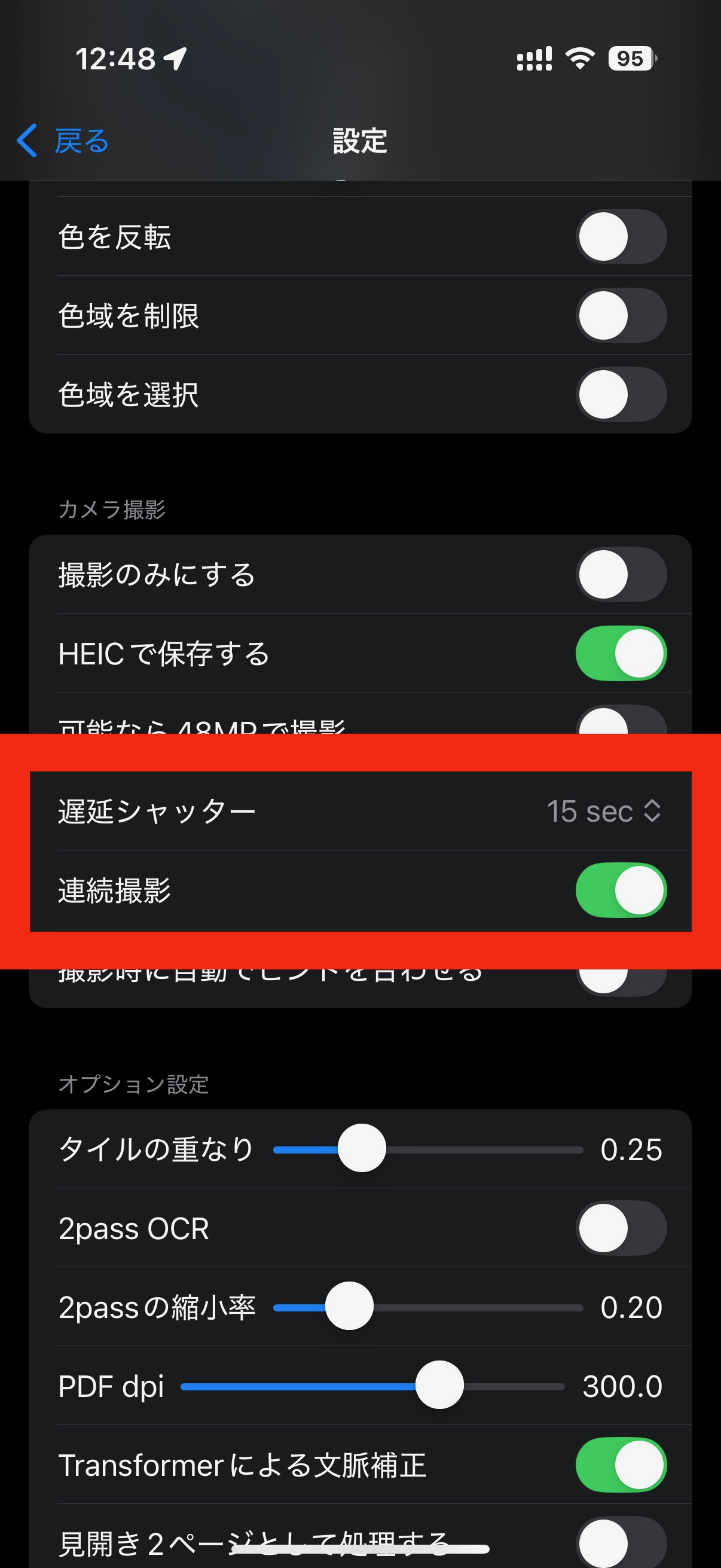
iPhoneを固定して撮影する際、両手で本を押さえたいことがあります。 遅延シャッターを使うと、撮影ボタンをタップした後に時間猶予をおいてから、実際に撮影されます。 ボタンを押してから、猶予時間に両手で本を上手く固定して撮影することができます。
遅延シャッターと、ピントの自動調整を同時にONにすると、時間猶予が終了した後にピントの自動調整を行い、合わせてから撮影されます。
連続シャッターをオンにすると、シャッターボタンを押したあと、再度押すまでの間、指定した時間間隔で撮影し続けます。 本のページを順番にめくりながら撮影し続ける、という使い方ができます。
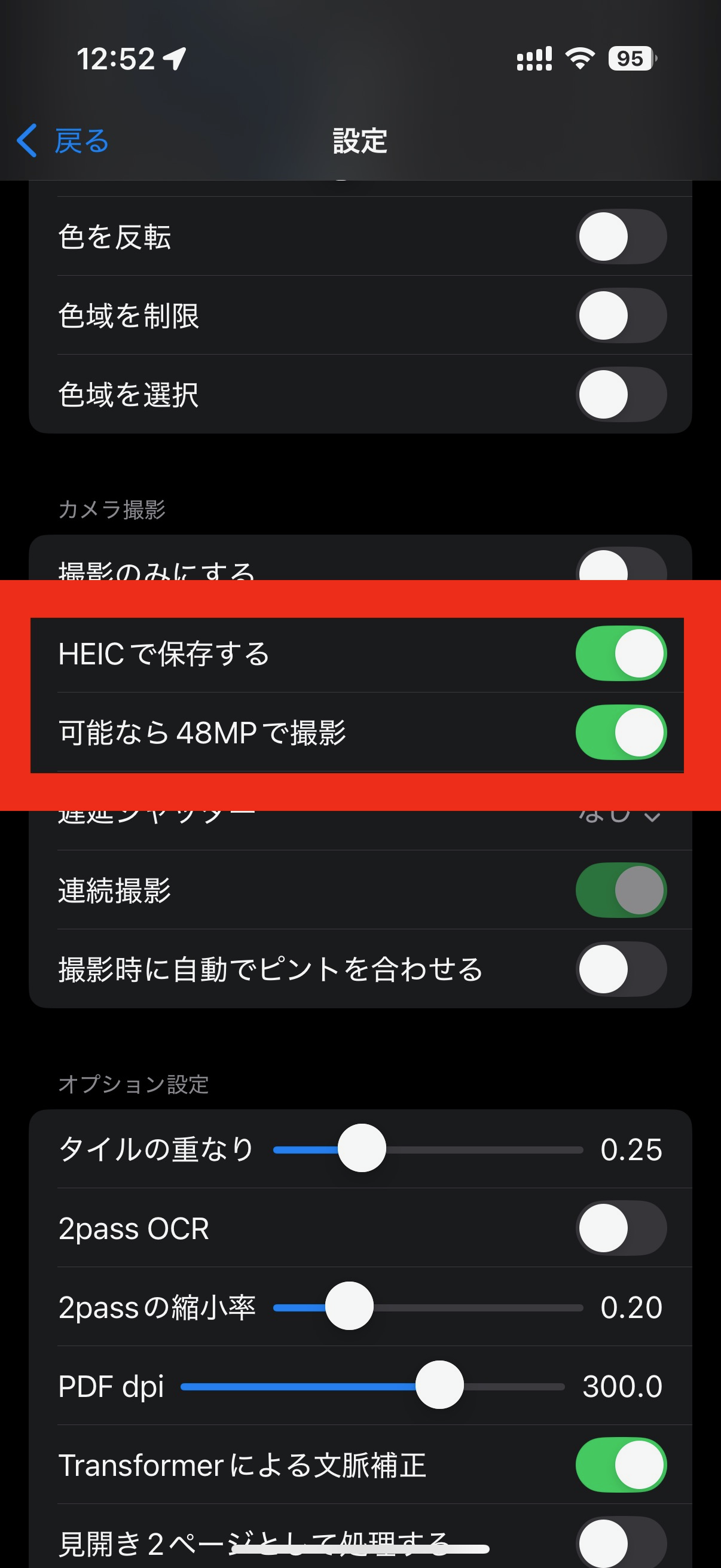
iPhoneの機種によっては、カメラでレンズによっては48MPが使用できることがあります。 細かい文字まで撮影したい、という場合に使用すると解像度を上げることができます。
内部で保存するフォーマットをpngではなくheic形式で保存すると容量を節約できます。
レンズの周辺部は、収差があって文字が歪んだりぼやけたりすることがあります。 また、解像度を上げるとサイズが大きくなり、OCR処理に時間がかかるようになります。 これらを回避するために、中央部分だけを切り抜いて使用することができます。
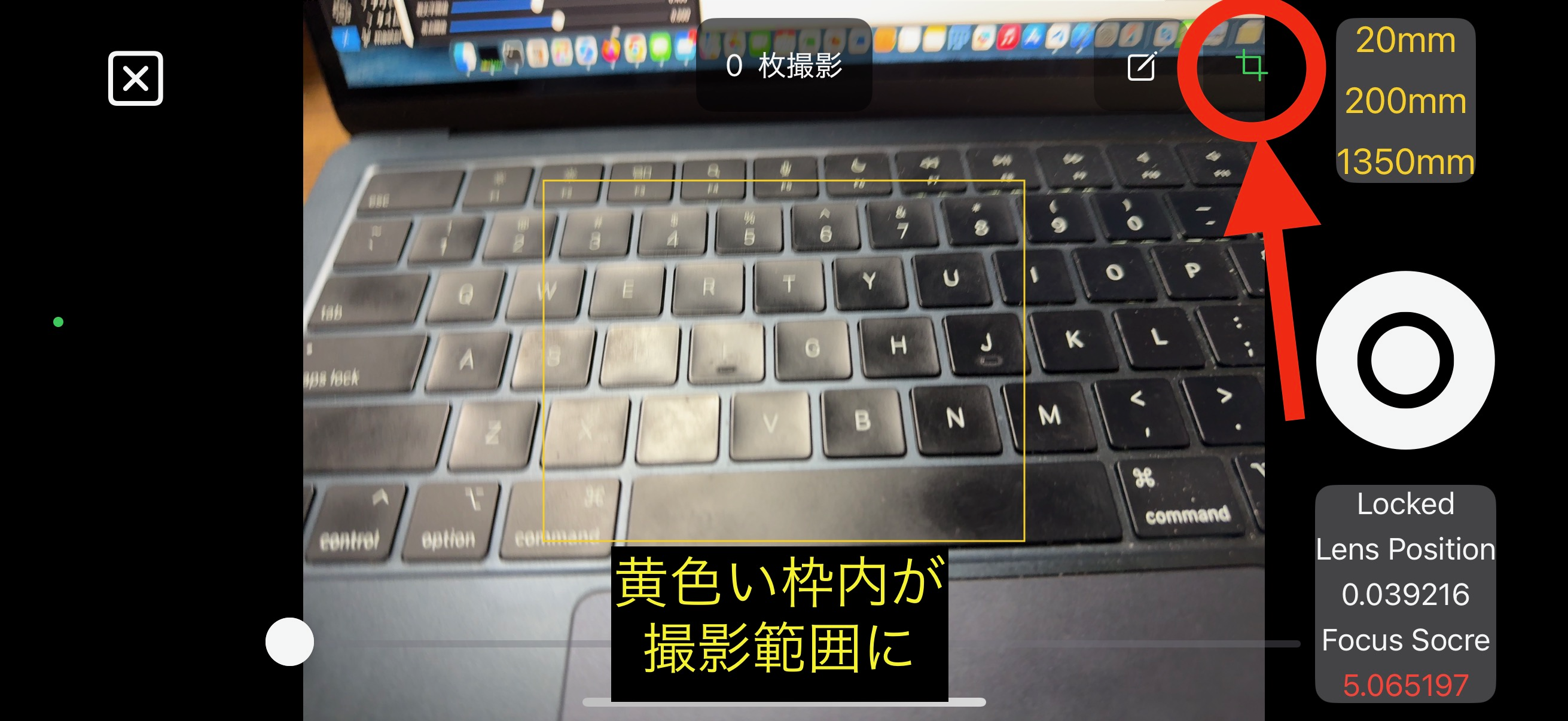
切り抜きボタンを押すと、画面中央部が1/2サイズで切り抜かれる枠が表示されます。 この枠が表示されている状態で撮影すると、枠内が保存され処理対象となります。

撮影範囲の枠は、サイズ変更や場所を動かすことができます。 枠編集ボタンを押すと、四隅に丸印が表示され、編集できます。 最後に枠編集ボタンをもう一度押して、編集結果を反映するのを忘れないようにしてください。
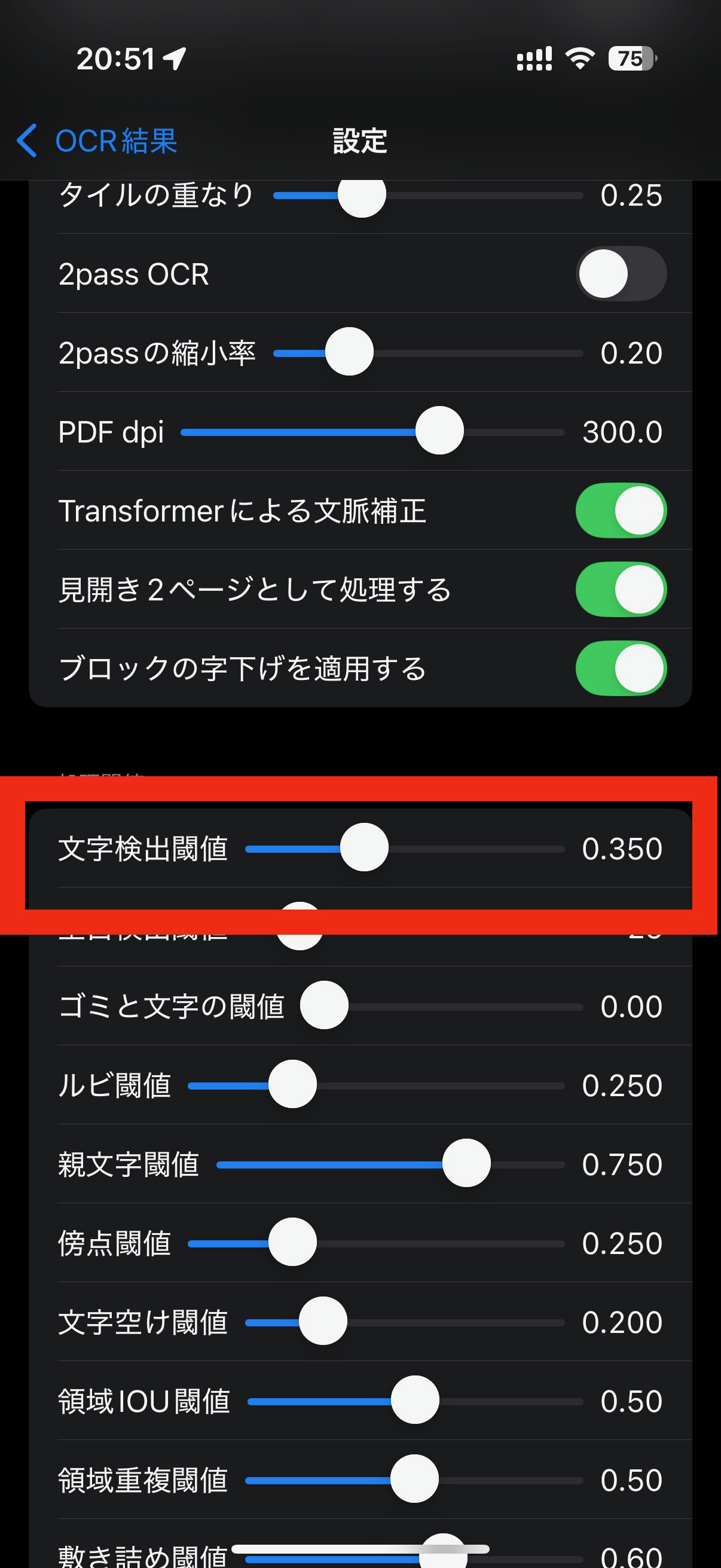
デフォルトのパラメータで、おおむねよい結果が得られるように調整してありますが、画像の状態によっては上手く認識できないときがあります。 その際は、設定からパラメータを微調整すると上手くいくことがありますのでお試しください。

文字検出閾値のデフォルトは0.35ですが、画像によっては適切でない場合があります。

この画像の場合、0.35では感度が高すぎて、背景の線まで誤認識しています。

文字検出閾値を0.45程度まで上げると、誤認識がなくなります。

画像処理の都合上、768ピクセル四方に画像を切って処理します。 そのため、処理する画像に写っている文字の大きさは、おおむね 16 pixel 以上で 300 pixel 程度以下、100 pixel 程度の大きさが望ましいです。
画像が小さすぎる場合、または大きすぎる文字が写っている場合等は、リサイズにより適切な画像サイズに変換するとよい結果が得られます。
オリジナルサイズの場合、画像が小さすぎるようで認識が上手くいっていません。

リサイズにより、2倍の大きさにすると上手く認識できるようになりました。ふりがなも認識できています。
機械学習モデルは、学習時にぼやけた画像や、エッジが綺麗な画像など多数与えて学習しているので、基本的にあまり調整する必要がありません。 入力画像があまりにぼやけている場合や、ディスプレイを撮影した画像などピクセルの四角が目立つなどして、認識が上手くいかない場合や、 カラー差が少なすぎて認識できない場合は、フィルタ処理をすることで改善するかもしれません。

以下のフィルターが適用できます。
| ガウスぼかし半径 | 0より大きくすると、その半径ピクセルでガウスぼかしをかけます |
| 鮮鋭化 | アンシャープマスクフィルタの強度と半径を指定します |
| 彩度 | saturationを調整します |
| 輝度 | brightnessを調整します |
| コントラスト | contrastを調整します |
以下の画像のように、OCR処理しにくい画像の場合は、詳細表示画面で画像をオリジナル表示にして、 右下にある "PreProcess" ボタンからフィルタ処理を試しながら調整することができます。
 画像の引用元
https://x.com/shibayan/status/1702575226985623981
画像の引用元
https://x.com/shibayan/status/1702575226985623981
"PreProcess" ボタンを押すと、画像下部に設定画面の画像処理設定と同じ調節メニューが出ます。 なにか設定して、"Done" ボタンを押すと、設定した前処理パラメータで実際に処理した画像が表示されます。

色域を制限というオプションで、画像のカラー輝度値の上限と下限を設定することができます。

この場合は、必要な文字は黒で、背景はそれより全て明るいので、上限を非常に低い輝度値に設定することにより次の結果を得ます。

色域を選択というオプションで、画像の中から特定の色とその類似色だけを選択できます。

「選択の色」というオプションで、選択の中心となる色を指定できます。スポイトを選ぶことにより画像から色を拾うことができます。 次に、H range, S range, V rangeを設定します。選択の色をHSV空間にしたときの範囲で、選択色を選びます。
地の模様である文字を取りたい場合、スポイトで文字から色を拾って、HSVを適切に制限すると次の結果を得ることができます。

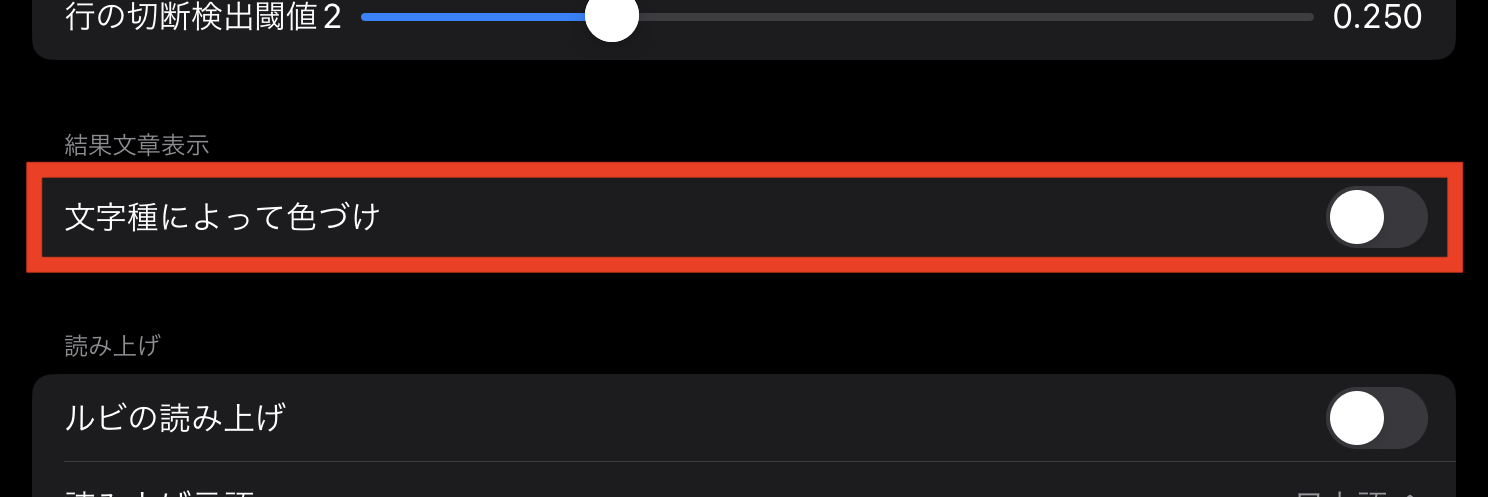
結果の文字列は、ふりがな有りで表示されますが、カタカナや漢字の紛らわしい文字と入れ替わっていないか確認したいときがあります。 その際は、文字種によって色づけをONにすることで、ひらがな、カタカナ、漢字、及び「ぱぴぷぺぽ」に色が付いて表示されます。

画像を768ピクセル四方に切って順次処理しますが、重なりの部分を作らないと境目で文字認識に失敗します。 あまり重ねると冗長で時間がかかるので、デフォルトの25%くらいが適切だと思われます。 大きい文字が多い場合などは、50%程度まで重なりを増やすと、繋ぎ目の誤認識が減ります。

画像の中の文字の見かけのサイズが、おおむね 16 pixel 以上で 300 pixel 程度以下、100 pixel 程度の大きさであると上手く認識します。 大きい文字と小さい文字が混じっている画像では、この条件をリサイズでは満たせない場合があります。 その際に、多段階でリサイズして処理することで改善することがあります。

ONにすると、この設定では縮小率が0.2なので、元のサイズと、768ピクセル四方に収まるまでx0.2倍に順次縮小していった画像から、それぞれ認識させて重複を排除して結果とします。
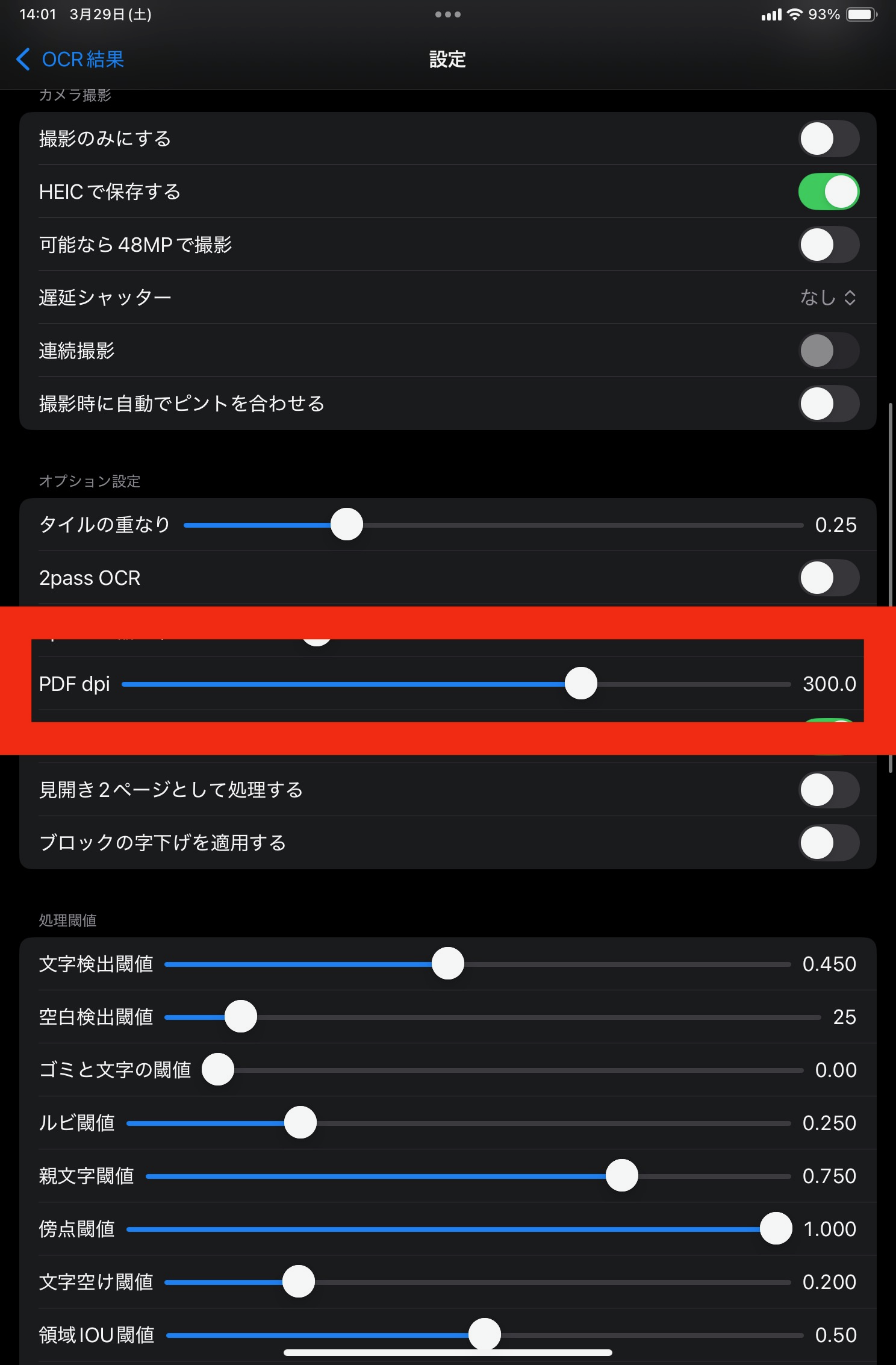
pdfを画像としてOCRする際に、dpiを設定できます。 この設定の解像度として画像が書き出されて、認識処理されます。 dpiを上げると、見かけの文字サイズが大きくなります。
OCR処理は、2段階に分かれていて、文字の位置と特徴量を検出した後、文の方向に並べてTransformerにより文字列にしています。 Transformerによる後段の処理は、文字数が多くなるのに比例して遅くなります。 デフォルトでONですが、高速化したい場合や前段だけで十分な精度が得られている場合はこれをOFFにすることもできます。 現在、Transformerの部分の学習がいまいちなので、たまに誤った結果が得られることがあります。 OFFにする方がよい結果を得られる場合もあるので、お試しください。

画像を見開きで撮影した場合、段組の読み順がページ内で読んでから次のページに移るため、単ページの処理と順番が異なります。


将来的にはフォーマット解析まで自動で行いたいですが、現時点では見開きの順の処理を手動で設定する必要があります。
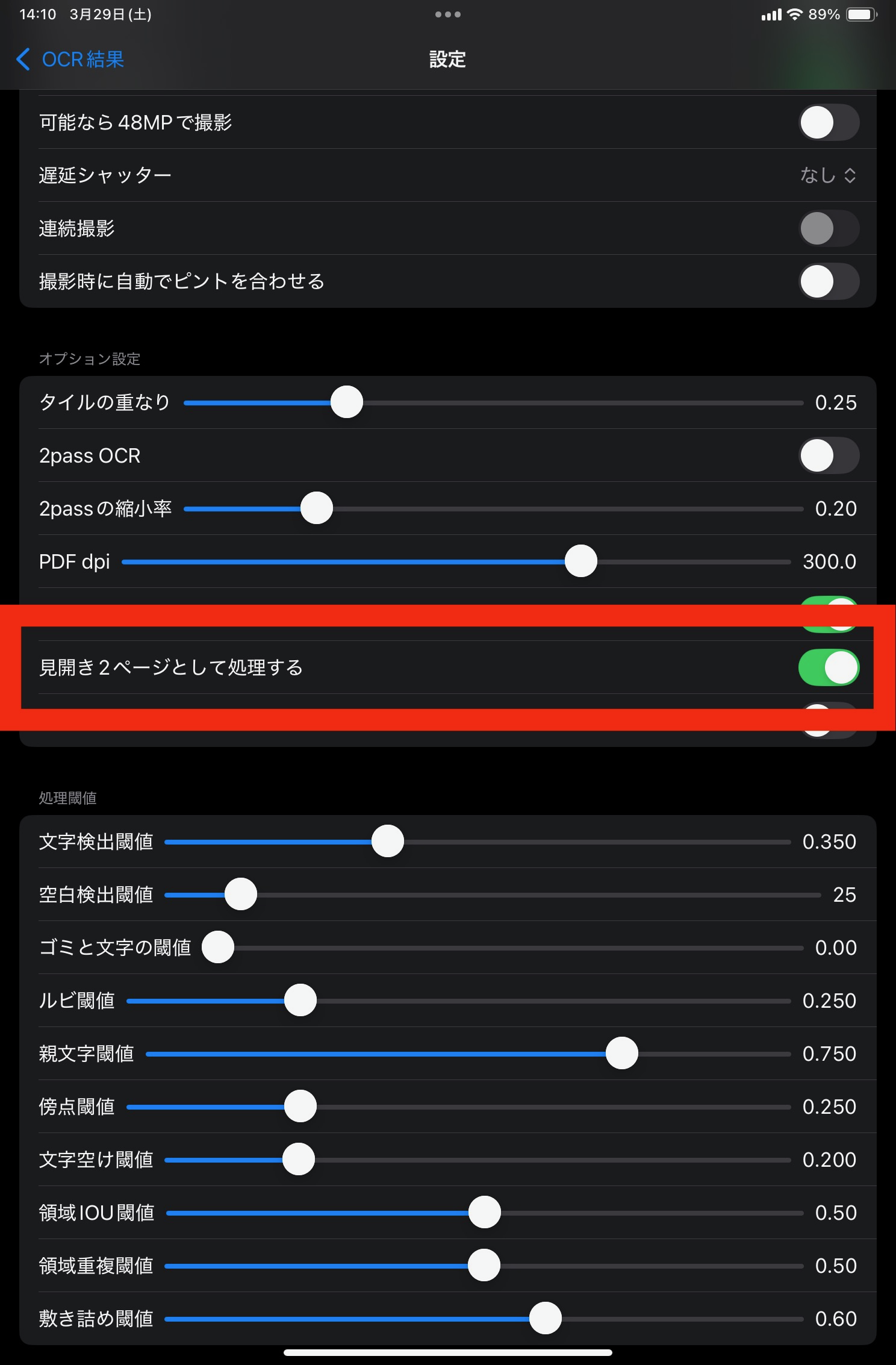
後述の本文以外の場所を推定する処理を行う場合にも、見開きと単ページで処理内容が異なるので、見開きで処理する場合は設定する必要があります。
認識モデルの学習の都合上、他と分離されたブロックが丸々字下げされている場合は、そのブロックは字下げされていないことがあります。 処理している視界に、他の行が入っている場合は、相対的に下がっていることが分かりますが、この例のように孤立している文が字下げされていると、 一部分を見ている段階では、判定がつかないことになります。


また、この例での、章番号4は普通の字下げよりもインデントが深く、この行は独立しているべきです。
改行を除去するモードで、ページ境界などを開けないオプションをONにしていると、以下のように章番号の前に改ページがあるため、 この部分が無視されて前の行との間に1行空きません。

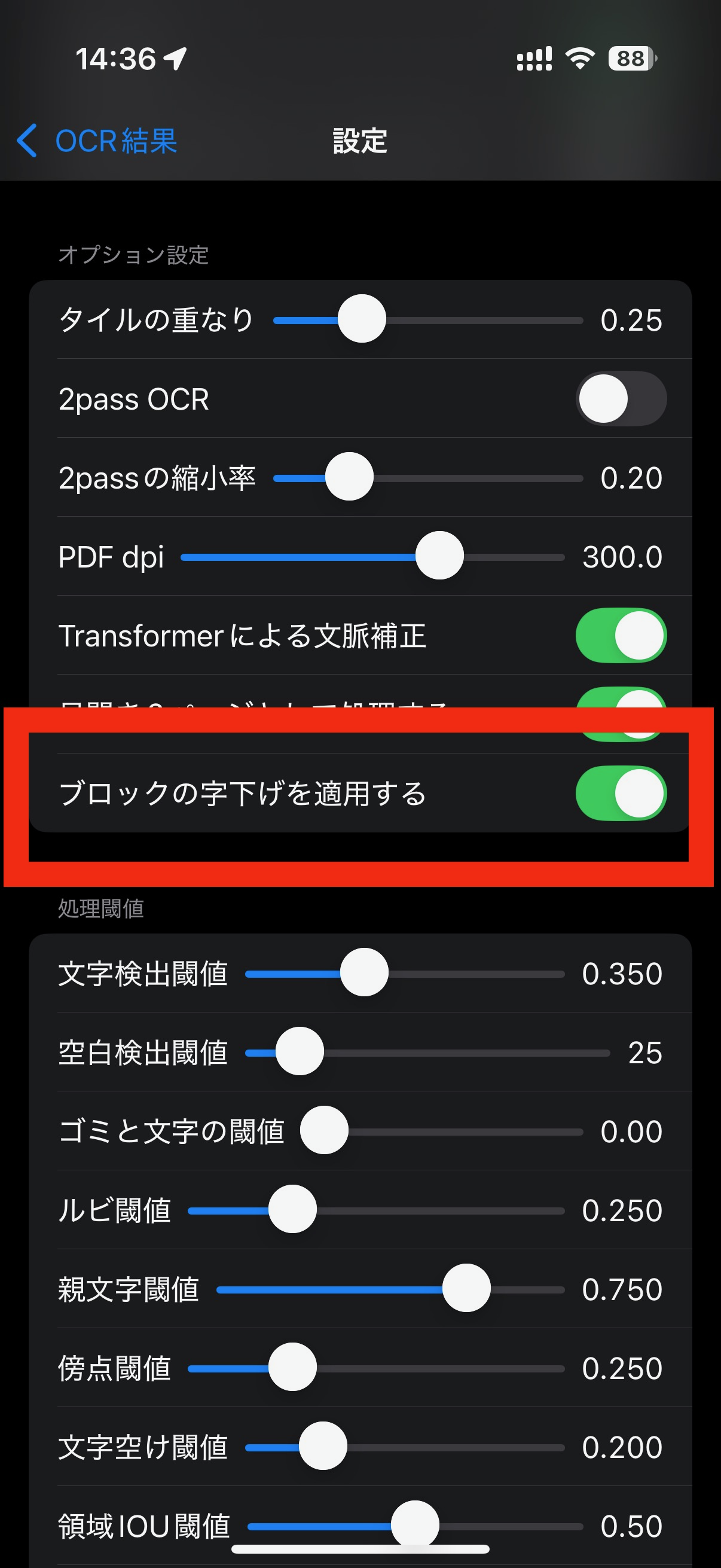
こうした状況では、「ブロックの字下げを適用する」をONにすることにより、同じ段落の周囲のブロックより、相対的に下がっているかどうかが探索され、字下げが行われます。
また、章タイトルのように大きく字下げされている行は、改行を除去するモードで、ページ境界などを開けないオプションをONにしていても、前の行との間に空行が挿入されるようになります。

デフォルト値は0.35ですが、かなり感度が高い状態です。

漫画などのように背景に線が入っているものや、手書きのテキストなど誤認識が多いものは、閾値を上げると余計な部分が外せることがあります。 逆に閾値が高すぎると、本来取れるべき文字まで取りこぼすことがあります。 0.5付近を目安に調整するとよいと思われます。
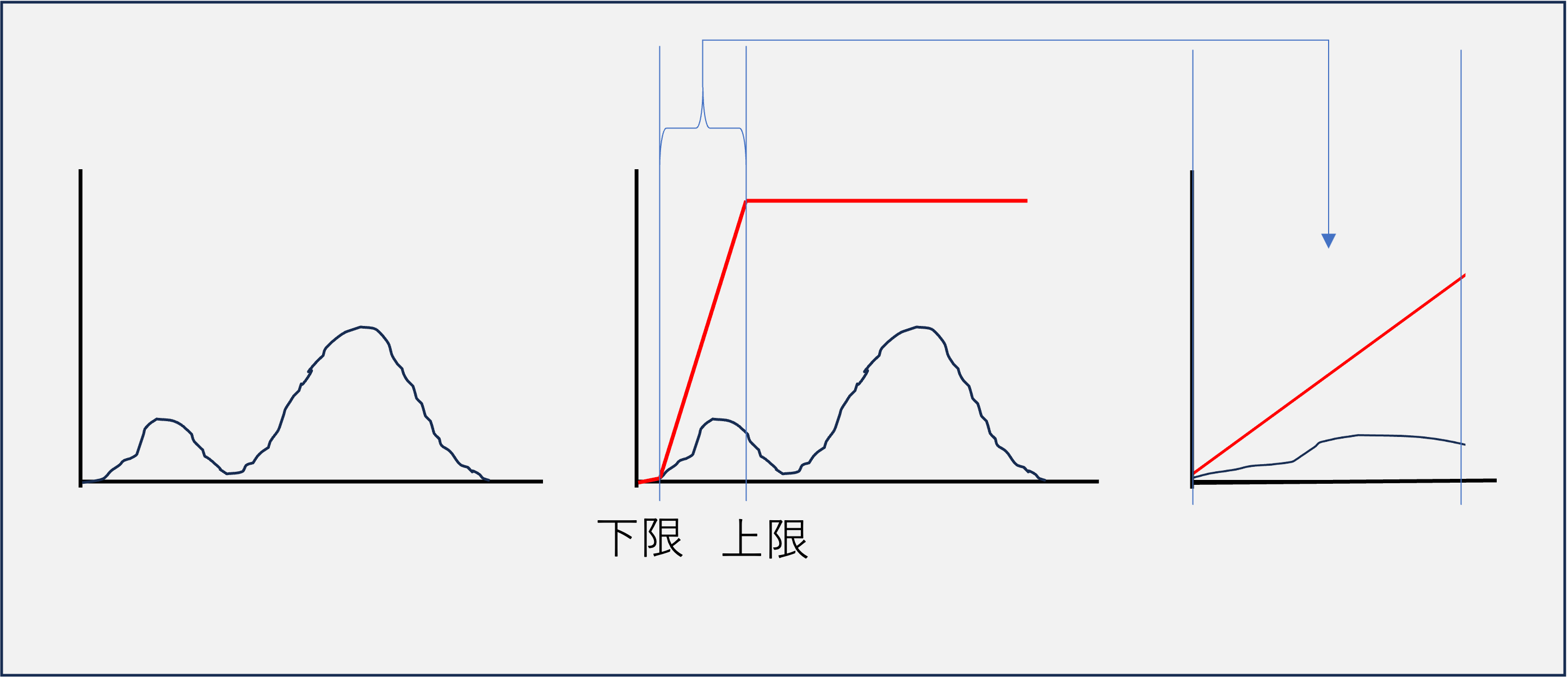
文字のある領域は、輝度値でヒストグラムを描くと、文字の明るさのピークと、背景の紙の明るさのピークのふた山のピークになります。
一方、文字でない領域が誤認識された場合、背景の紙しかありませんので、ピークが1つになります。 また、小さなゴミを拾った場合、ゴミの明るさと背景の紙の明るさの差が、本来の文字の明るさと背景の紙の明るさの差に比べて小さい場合がほとんどです。
このことを利用して、誤って検出された背景の部分のBOXを検出することができます。
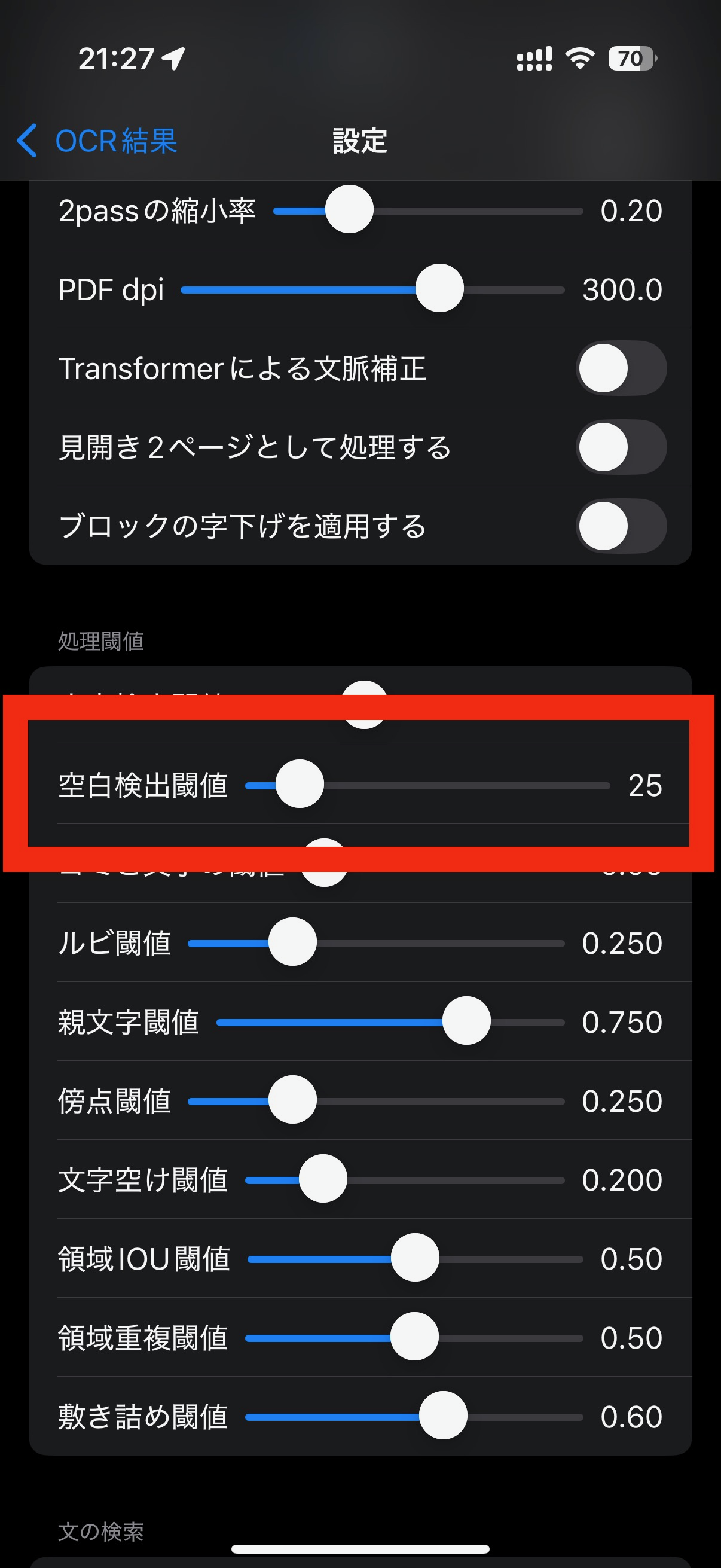
デフォルト値は25です。 値を上げると、よりはっきりした文字のみになります。 値を下げると、ぼんやりした文字まで取得できます。


文字検出閾値が低くて感度が高い状態だと、紙の裏写りの文字を拾ってしまう場合があります。(空白検出閾値=0として処理した例) こうした場合に、空白検出閾値の値を上げることにより、裏写りのゴミを外すことができます。



ピントボケの画像であったり、字が薄い文字を検出したい場合は、空白検出閾値=25では取りこぼすことがあります。 この場合は、もう少し下げると認識することができます。
裏写りした文字や、印刷のゴミを認識した場合は、たいてい文字として認識することが困難である為、検出確度が低く出る傾向にあります。 このことを利用して、文字でない部分を認識してしまったBOXを外すことができます。
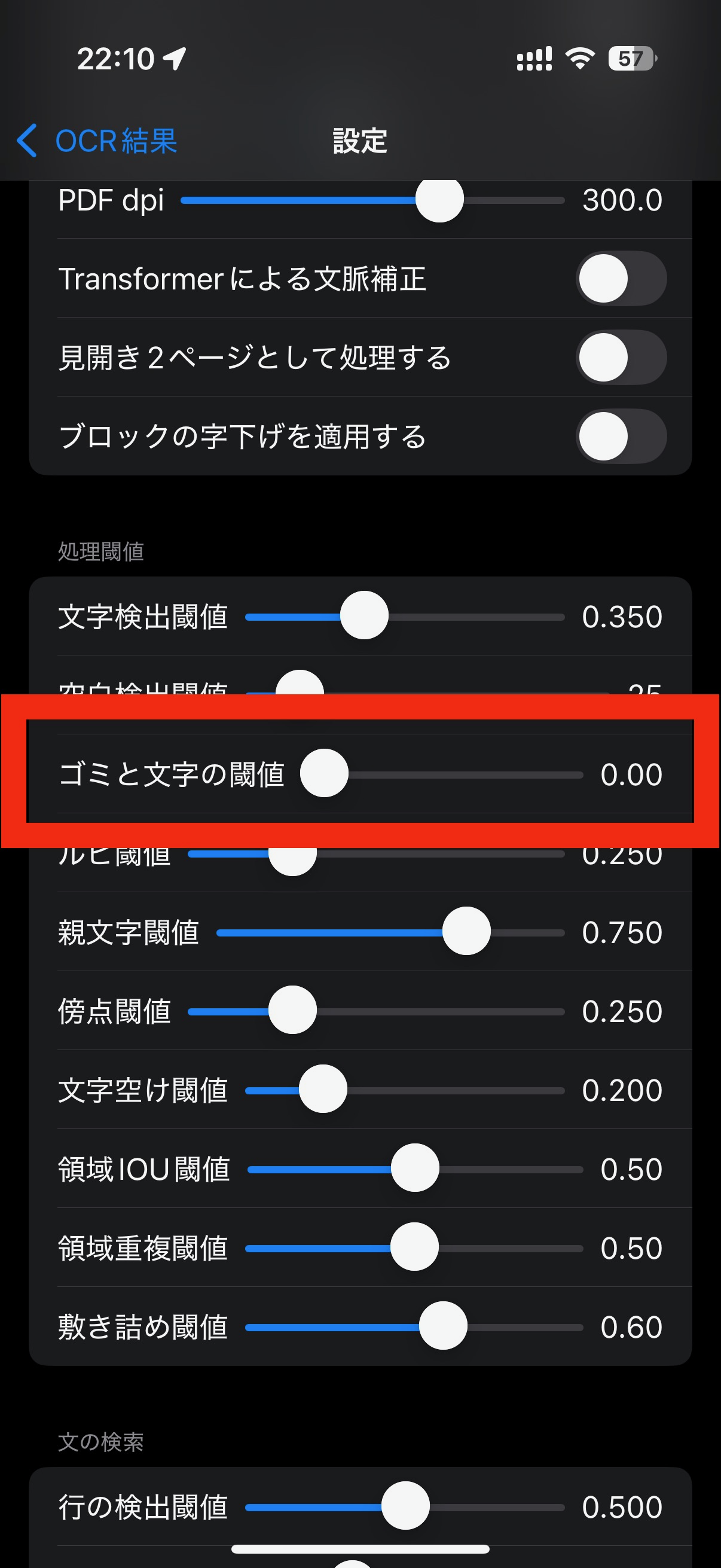
デフォルト値は0で、使用しない状態です。 印刷が不明瞭な場合、本来の文字まで検出確度が低く出る場合もあるので、安全のために外しています。 鮮明なフォントの画像では、印刷のゴミを外すために0.05程度に設定するとよいでしょう。

はっきりとした文字で裏写りしている場合には除くことができませんが、裏写りの文字を軽減することができました。(ゴミと文字の閾値=0.5)

ふりがなの検出、圏点の検出、空白または字下げの検出の閾値です。 閾値を下げると感度が上がります。
文字空け閾値の0.3はかなり感度が上げてありますので、過剰に反応している場合は0.5程度まで上げるとよいと思われます。
ふりがな、傍点については、単独で属性がセットされたとしても、ふりがなの親文字が検出されない限り無視される設定なので、感度を上げておく方がよいです。
一方で、ふりがなの親文字については、かなり閾値を上げて感度を下げておかないと、隣の漢字にまでふりがなが侵略していくことになるので、デフォルトでは高めにしてあります。
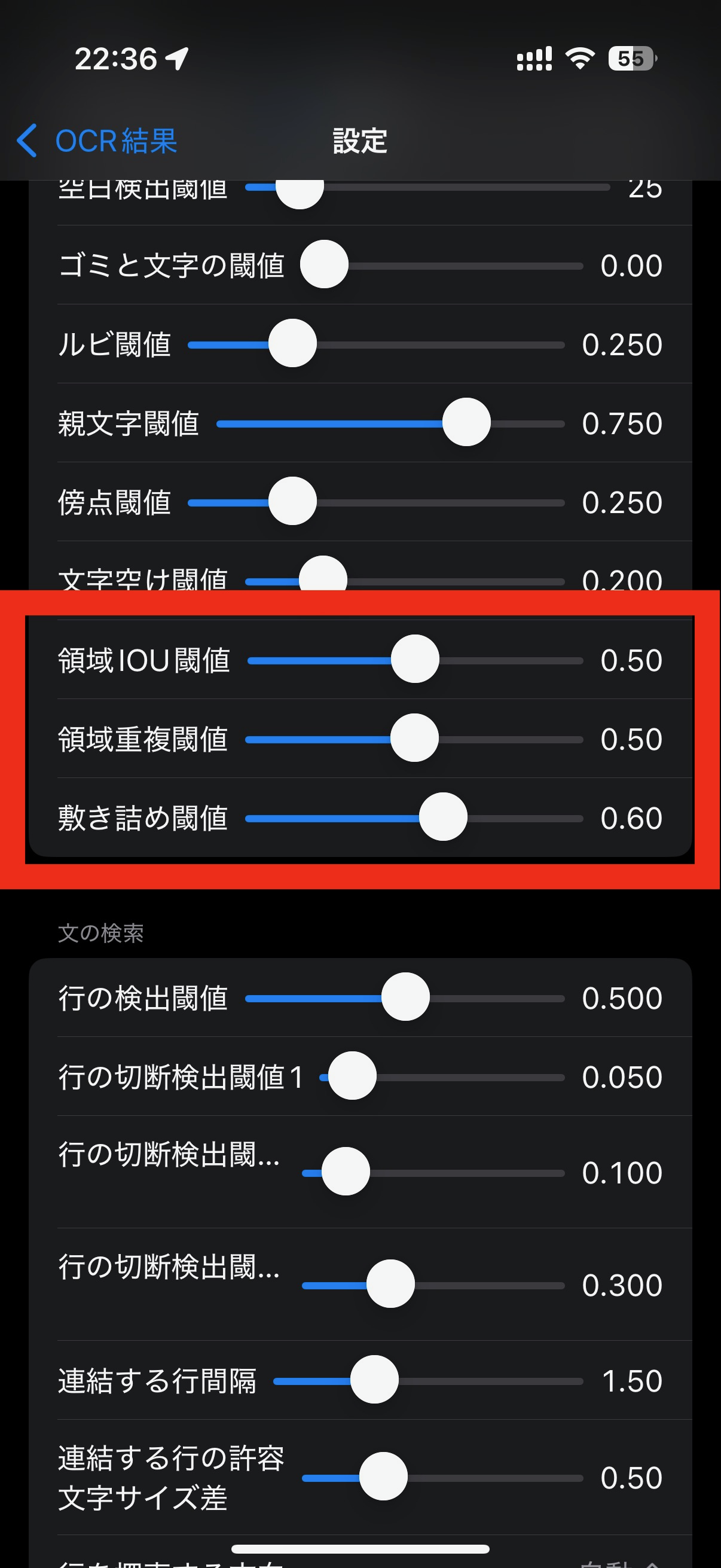
画像を処理する際に、少しずつ重なりのあるようにして分割して処理します。 そのため、重複して処理される領域があり、この部分でBOXが二重に検出されることがあります。 また、文字の構成上(偏と旁とか)2通り以上に検出可能な場合などに、BOXが重なってしまいどちらかは嘘であることがあります。 そうした状況を検出し、確度が高い方のみを答えとする処理の為の閾値です。
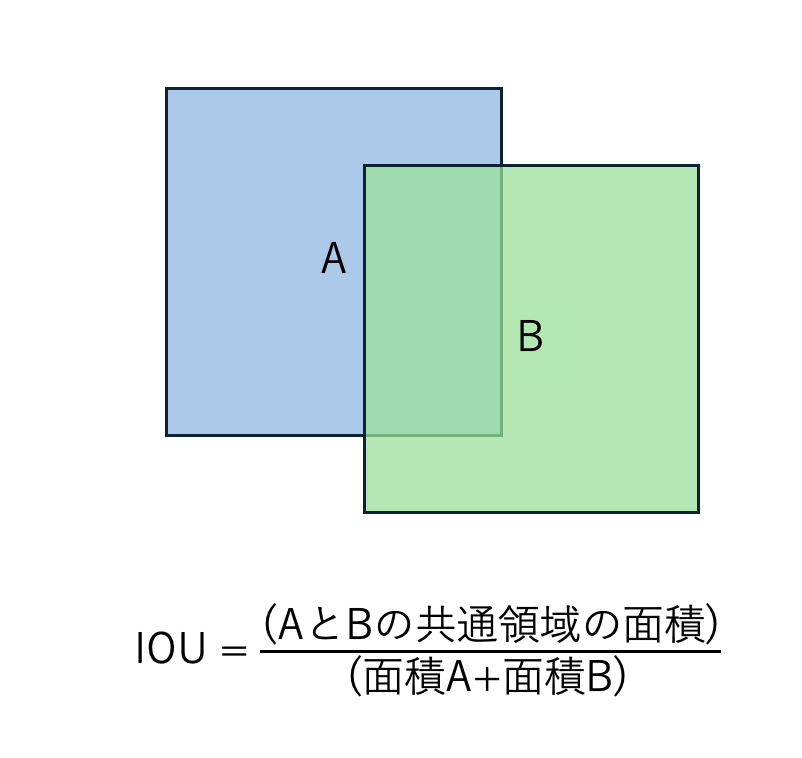
一般にBOXの重なり検出にはIOUという指標が用いられます。
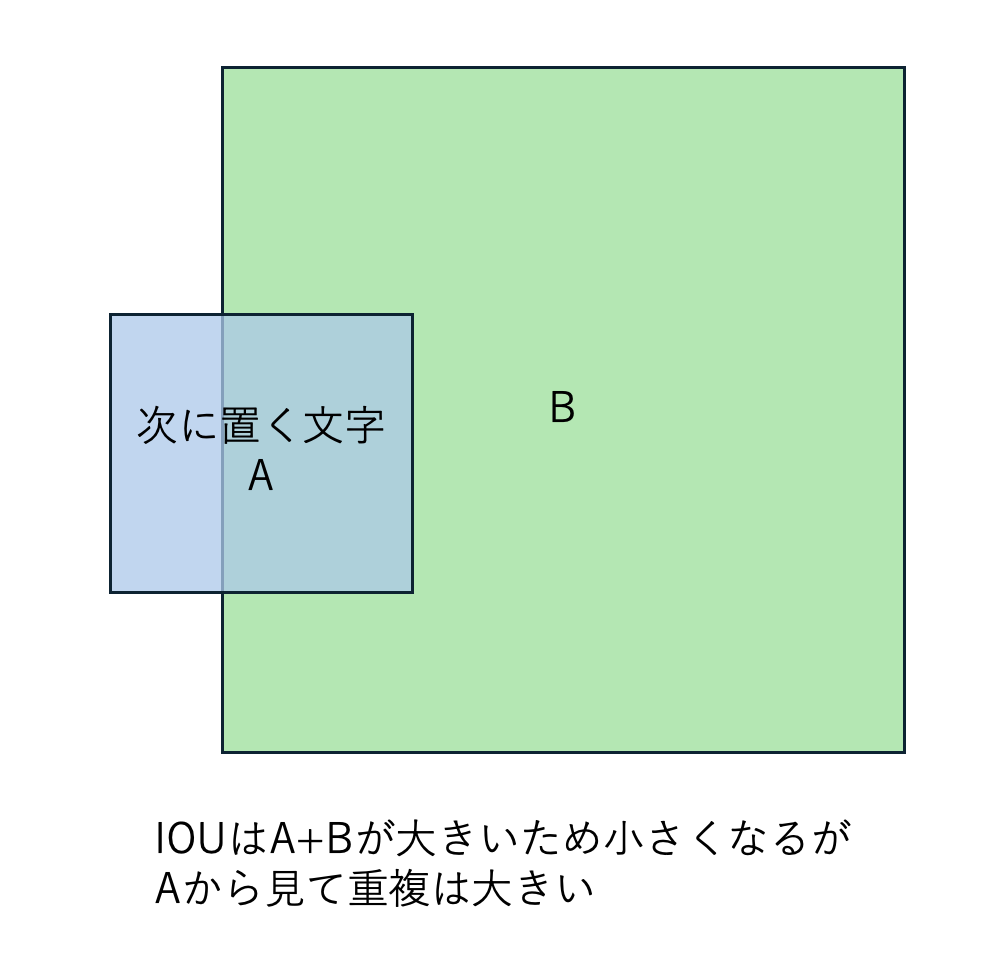
領域重複閾値では、IOUで分母がA+Bのところ、次に置く文字Aの面積だけを分母にします。 つまり、次に置く文字の面積からみた、重複領域の面積との比いう指標です。
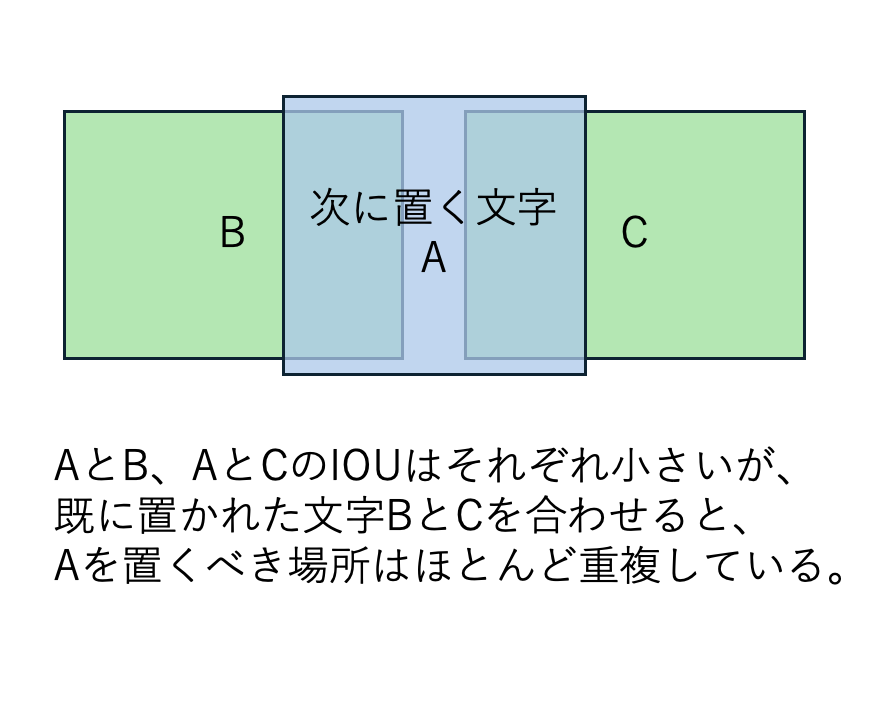
敷き詰め閾値では、2つのBOX間の重複検出ではなく、既に置かれた文字全ての領域に対して、Aの領域は空いているかどうかを調べます。 つまり、次に置く文字の面積からみた、これまでに置かれたいずれかの領域との重複領域面積の合計との比という指標です。
この機械学習モデルでは、文字の場所に加えて、文字がどっち方向に連続しているかを検出します。 これにより、縦書きなのか横書きなのかを判定することができます。
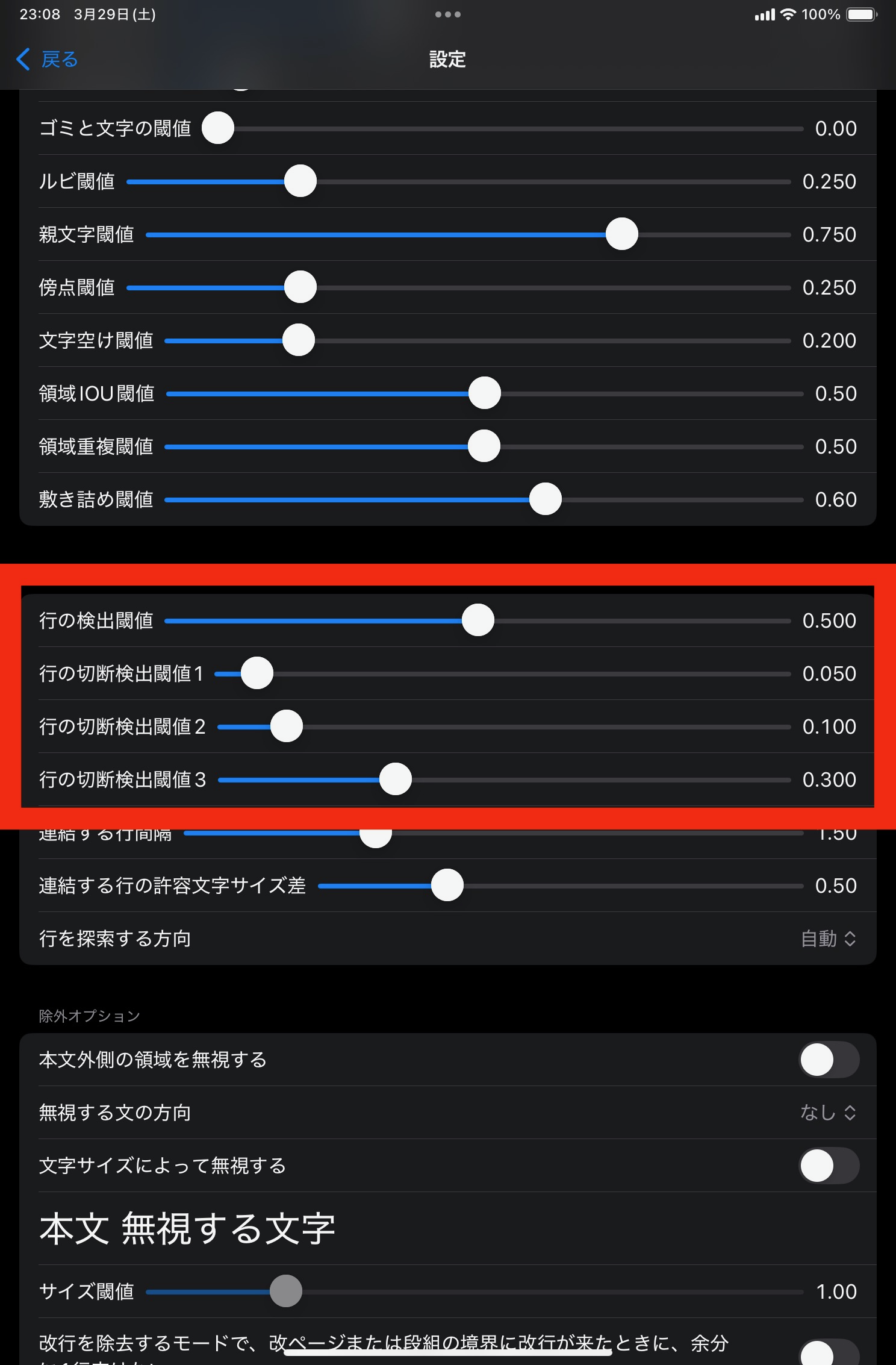
行の検出閾値では、文字の連続方向を検出するラインの検出感度を指定します。 あまり低い値を指定して感度を上げすぎると、関係の無い方向に文字が繋がってしまいます。
行の切断検出閾値では、段組の境目や、枠線、仕切り線などで、文が連続してはいけない場所を検出します。 ここで検出された壁を越えて、行は連続しないようにします。 検出は結構難しいらしく、確度はあまり高く出ません。 段組を検出する場合は、かなり低めの値で感度を上げると良いでしょう。 一方で、句点が横に並んでいると、そこが段に見えてしまう場合があります。こうした場合は感度を下げるとよいでしょう。
行間を設定します。 デフォルト値は1.5行(文字サイズの1.5倍)です。 行間が空いている文章の場合、隣の行に届かなくてブロックが切れてしまうことがあるので、行間を広く設定します。 一方で、あまりに大きい値を指定すると、句読点の隙間から2つ隣の行に触ってしまう場合があるので、このときは狭く設定します。
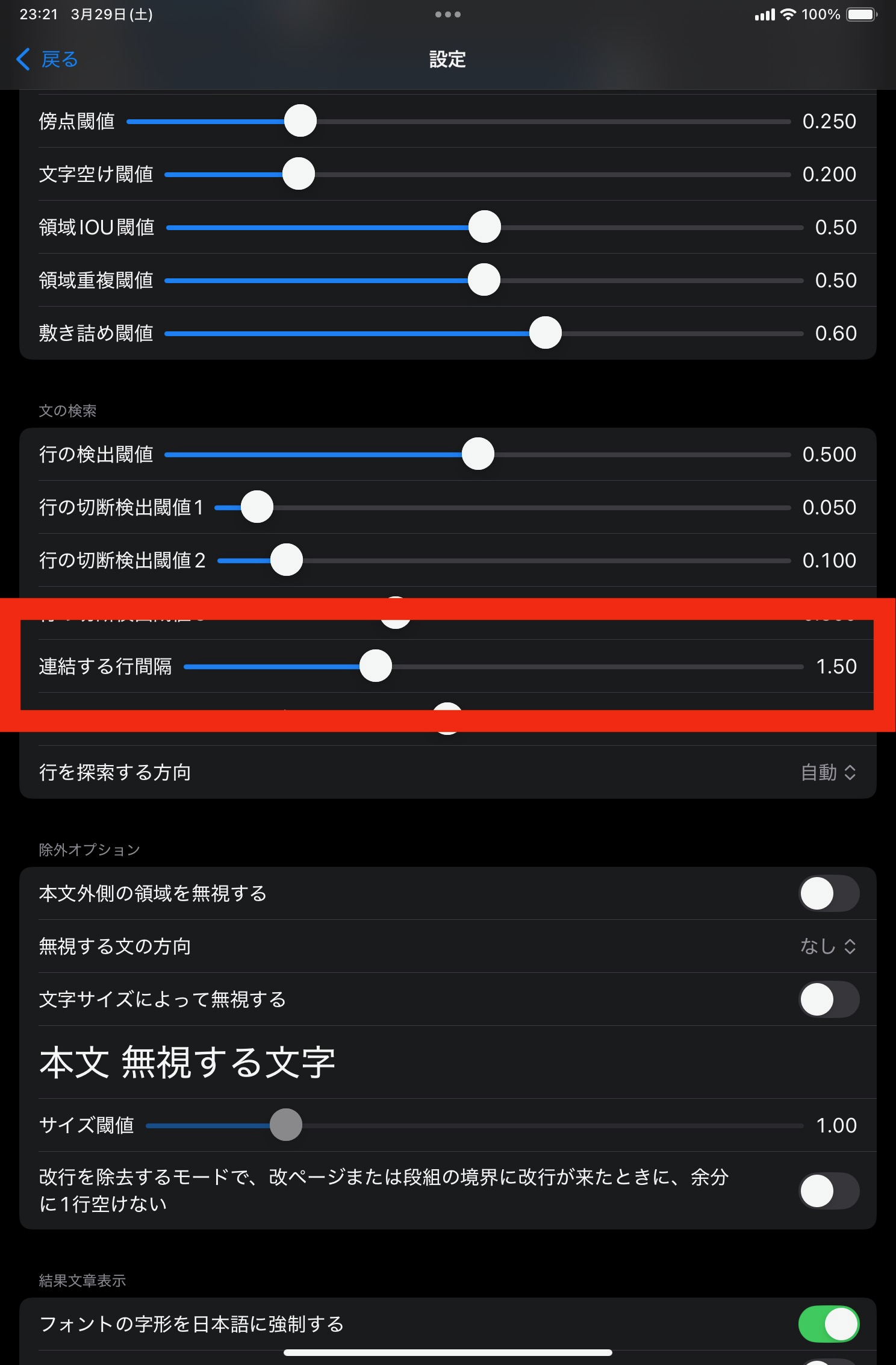
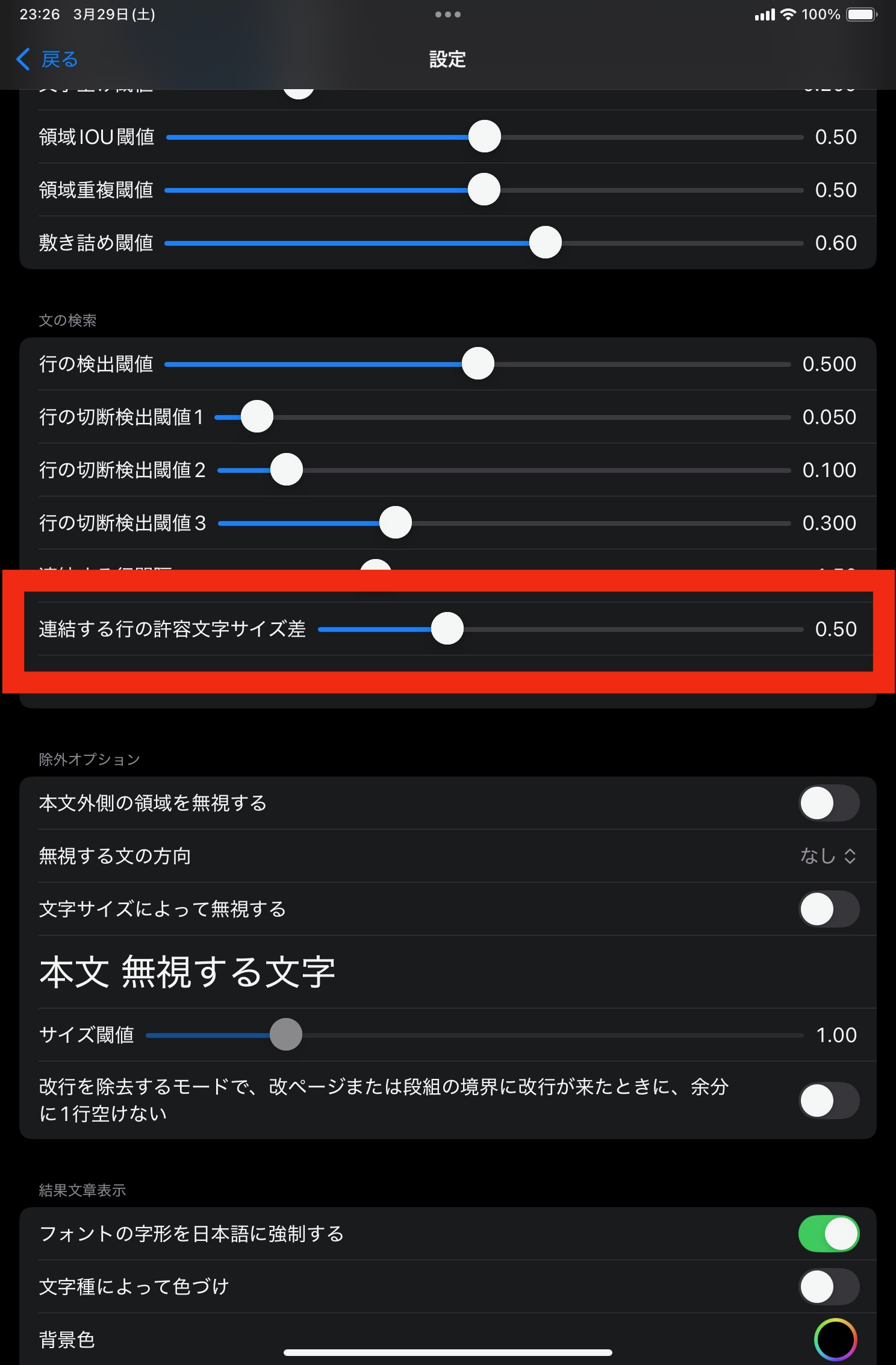
すぐ隣にある文でも、見出しと本文のブロックを分ける必要があります。 これを検出するために、連結時に文同士の文字サイズ差を調べます。 文字サイズ差が設定値より大きい場合は、文が近接していても連結しません。
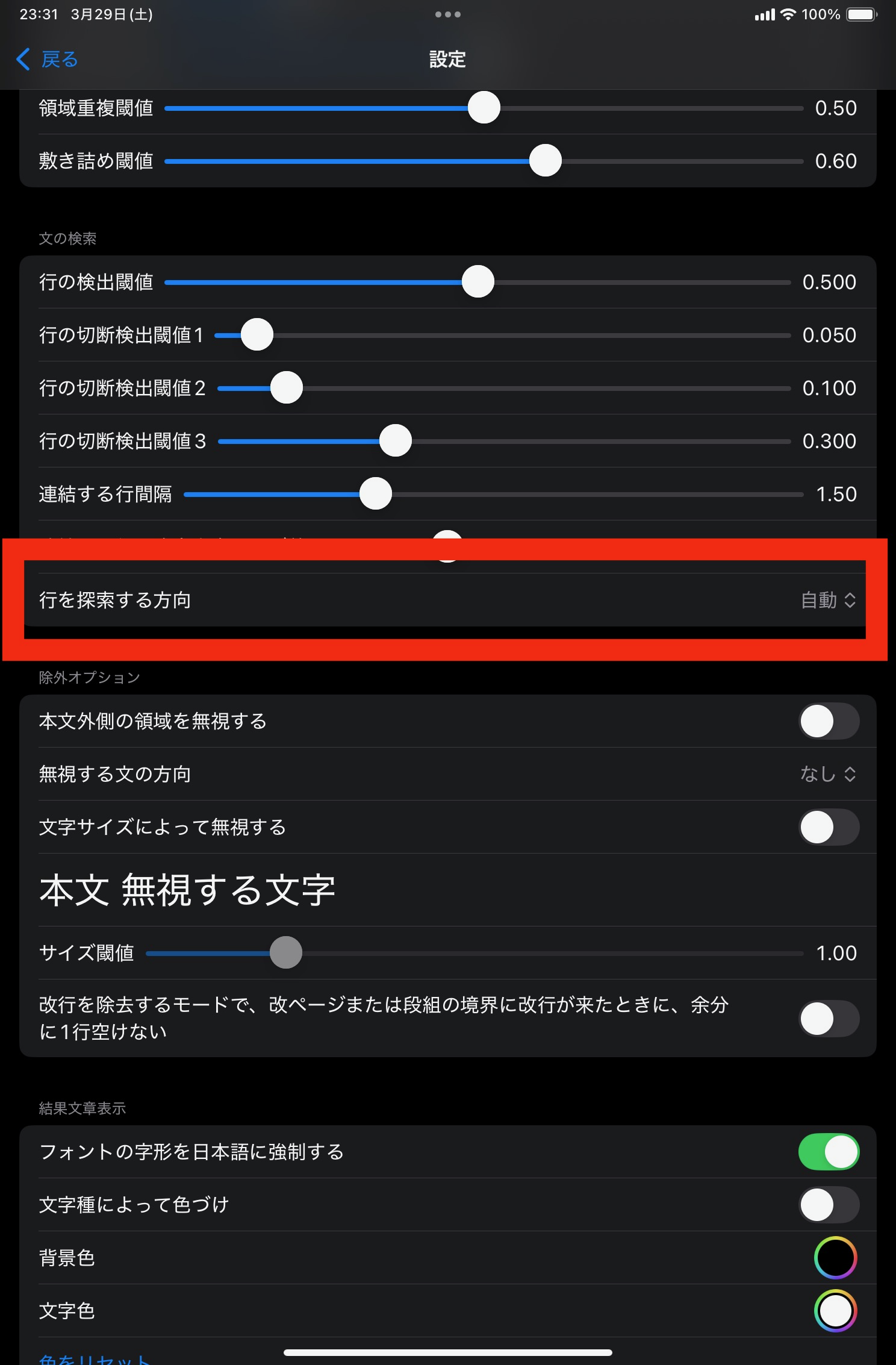
文章が縦書きか、横書きか事前に分かっている場合は、行の探索方向を指定することができます。
横書きであっても、1文字だけの行が連続すると、その部分が縦書きに検出されることがあります。 これを防ぐことができます。
よく似たオプションに、除外オプションに「無視する文の方向」というのがあります。 こちらは、検出した上で後から除外します。
現在開発中ですが、暫定的に実装しています。 縦書きの一般的な文庫本の場合、本文の上部か下部にページ番号と章タイトルが来ます。 これを検出して除外します。
検出した文を、方向によって無視します。
ページ番号など要らないところが、本文に比べて小さい文字である場合には、サイズ差によって無視することができます。
作者に、認識に不具合のある画像データを送りたい場合は、https://lithium03.info/upload/ からサーバーに送付することができます。