楽曲の楽器の分離
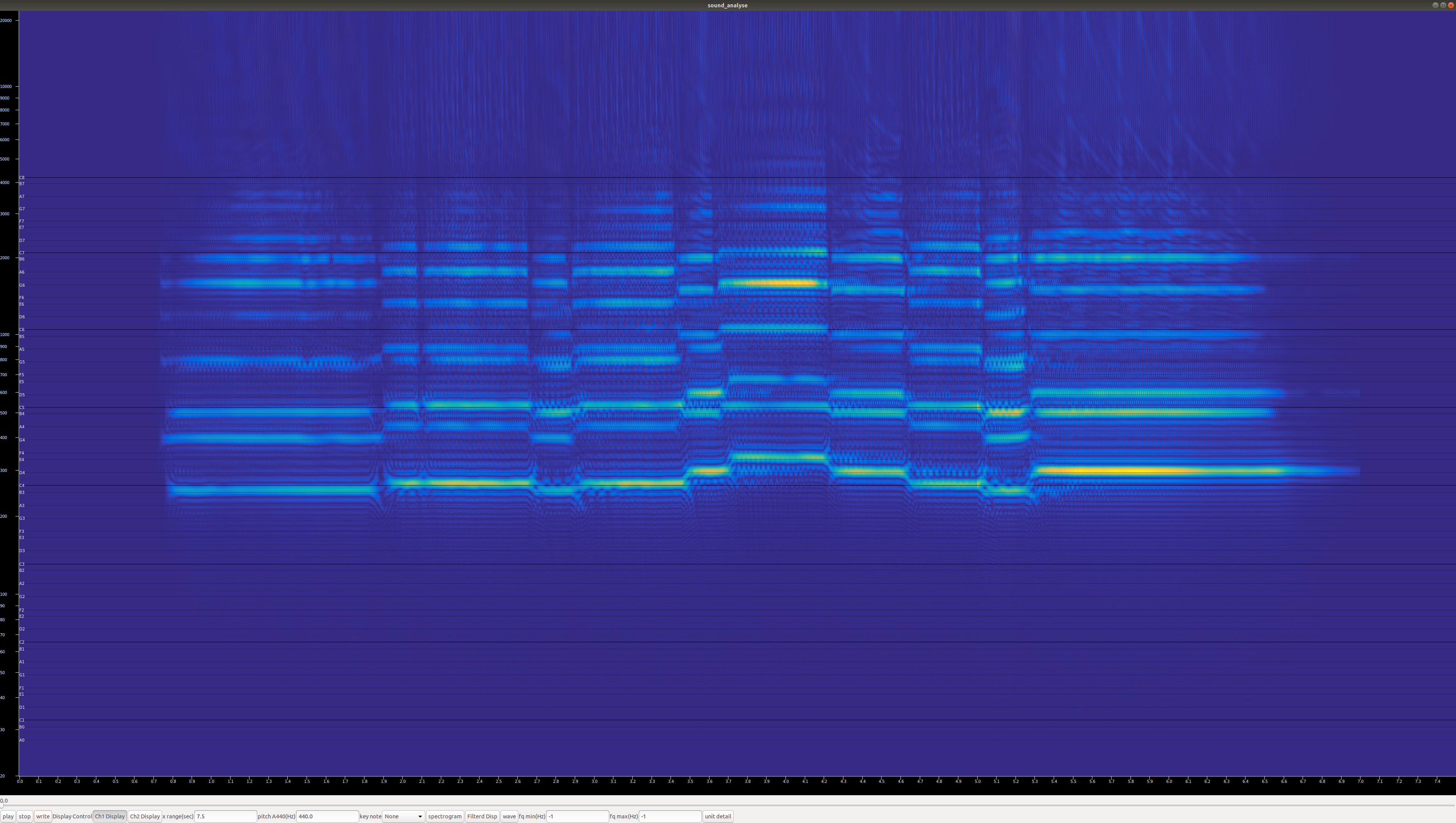
これまでに、周波数解析を行い、ピークを指定すればその信号がおおむね抽出できるようになりました。 それでは、実際の楽曲から一部が分離できるか試してみます。 ここでは、非常に条件の良い音源が手元にありましたので、2つの楽器がそれぞれ分離できるか実験します。
"愛を見つけた場所" トランペットとユーフォニアムの楽曲
今回使用する音源は、
TVアニメ『響け!ユーフォニアム』オリジナル・サウンドトラック おもいでミュージック amazon linkの冒頭7secの最初のフレーズ部分です。
Disc 2/12曲目
愛を見つけた場所
( 作曲 : 奥 華子 / 編曲 : 松田彬人 / 演奏 : 黄前久美子 , 高坂麗奈 / Euphonium : 円応寺博行 , Trumpet : 上田じん )
分離のロジック
これまでと同様に、周波数解析を行い手動でピークを指定して成分の抽出を行います。 今回は楽器ですので指定した周波数の他に、高次倍音も同時に抽出することとします。 手動でピークを指定する際、音が途中で変化しているところでトラックに失敗します。 これを防ぐために、音の変化点の前後のピーク位置をそれぞれ指定してピークのトラックが失敗しないようにします。
内部の抽出ロジックは、指定されたピーク点(seed point)から検索し、次のseed pointとの時間方向の中点までと 前のseed pointとの時間方向の中点からの部分を、現在検索中の周波数をトラックしているものとして検索します。 こうすることで、音の開始点と終了点をそれぞれクリックしてseedとして与えることにより、トラックが隣の成分に飛びにくくなります。
トランペットの分離
たくさんピークがあり分かりにくいですが、冒頭ほんの僅かにトランペットが早く入っています。 ここを手がかりに、トランペットの高次倍音とユーフォニアムの高次倍音をよく見てみると、最初の音はG4で(ユーフォニアムはB3) そこからG5に第2倍音が、D6にうっすらと第3倍音、G6に第4倍音と続き、だいたい9次倍音くらいまでは見えていることがわかります。
以下のパラメータで分離を行いました。
start 27829(0.631051sec) 191.349 Hz @ 9 seed 33866(0.76795sec) 397.521 Hz seed 60182(1.36469sec) 395.538 Hz seed 82237(1.8648sec) 397.521 Hz seed 86158(1.9537sec) 439.462 Hz seed 95527(2.16615sec) 443.885 Hz seed 116308(2.63737sec) 441.663 Hz seed 118874(2.69556sec) 399.524 Hz seed 126682(2.87263sec) 397.521 Hz seed 130304(2.95476sec) 443.885 Hz seed 150397(3.41038sec) 441.663 Hz seed 154120(3.49479sec) 498.2 Hz seed 160893(3.64837sec) 495.714 Hz seed 162706(3.68948sec) 529.213 Hz seed 185356(4.2031sec) 529.213 Hz seed 187815(4.25886sec) 503.245 Hz seed 202982(4.60279sec) 500.71 Hz seed 206905(4.69174sec) 443.885 Hz seed 220444(4.99875sec) 443.885 Hz seed 223555(5.06929sec) 401.525 Hz seed 231400(5.24717sec) 407.602 Hz seed 235501(5.34017sec) 498.2 Hz seed 282340(6.40229sec) 500.71 Hz end 319696(7.24935sec) 8430.11 Hzseed pointの作成は、耳で聞いた音程をもとにスペクトラムをみて該当ピークを手動でクリックする手法で作成しています。

トランペット分離波形
結果の考察
音色がだいぶ劣化してますが、一応トランペットであることはわかるレベルで分離ができました。ユーフォニアムの音色は聞こえない状態にはなっています。
ユーフォニアムの分離
同様にユーフォニアムの分離を行います。スペクトラムよく見ると、3次倍音までは見えていますがそれ以上はトランペットのピークに隠れて見えません。 現在の抽出アルゴリズムでは、トランペットのピークがあるとそちらを認識してしまうため、3次より上の倍音は諦めます。
以下のパラメータで分離を行いました。
start 23228(0.52673sec) 190.394 Hz @ 3 seed 36314(0.823457sec) 249.443 Hz seed 80759(1.83129sec) 249.443 Hz seed 86723(1.96652sec) 264.885 Hz seed 116381(2.63903sec) 263.559 Hz seed 120117(2.72375sec) 248.197 Hz seed 127263(2.8858sec) 248.197 Hz seed 130339(2.95554sec) 266.214 Hz seed 152153(3.4502sec) 264.885 Hz seed 155466(3.52531sec) 295.725 Hz seed 162446(3.68359sec) 297.207 Hz seed 165822(3.76015sec) 335.186 Hz seed 184360(4.18051sec) 331.844 Hz seed 189564(4.2985sec) 295.725 Hz seed 203185(4.60738sec) 291.317 Hz seed 206979(4.69341sec) 262.246 Hz seed 220009(4.98888sec) 260.937 Hz seed 223608(5.07049sec) 249.443 Hz seed 230960(5.23721sec) 250.693 Hz seed 235516(5.34052sec) 300.204 Hz end 321651(7.29368sec) 8583.94 Hz

ユーフォニアム分離波形
結果の考察
高次倍音がないため、こもった音色になっています。また、トランペットのピークと近接している音では、トラックに失敗して音が揺れてしまっています。 一応音程はわかる程度には分離できることがわかりました。
楽曲の楽器分離のまとめ
音程と楽器がわかる程度には分離できましたが、オリジナルと比べることもできないほど劣化が激しくなっています。 様々な原因が考えられますが、伴奏が入ってきた場合を考えると、他の楽器の倍音でトラック仕様としている楽器の倍音がかき消されてしまう点が大きな問題です。 スペクトラム図のピークを取る方法では、本質的に解決できないということがわかりました。 音程をトラックする際に、人間の手で指定している点もあまり好ましくありません。 機械学習によるスペクトラム認識により解決できないか、これから探ることにします。