文字の場所が分かっているので、単純な分類問題になります。 しかし、日本語の漢字は常用漢字以上で2000文字程度、もっと頻度の低い漢字を入れると数千文字になります。 この数の分類問題になると、実装を工夫する必要があります。
単純に、分類してからテーブルを引けばよいのですが、DeepLearningで文字コードに変換するところも実装してみます。 UTF8文字列は、1byteずつ処理させると256パターンになるので処理しやすいパターン数です。 シーケンスを処理するのはRNNが真っ先に挙げられます。 確かに、RNNでも処理できますが、ここではひらがなが連続しているところのへとカタカナが連続しているところのヘで、 うまくひらがなとカタカナを区別できるようなシステムを目指し、Transformerのattention機構を使ってみることとします。
このパートのソースコードは、 https://github.com/lithium0003/Image2UTF8-Transformer にあります。
入力は、カラー文字画像 128x128x3 がN枚
出力は、UTF8文字列とします。最大で、4xN byteになります。
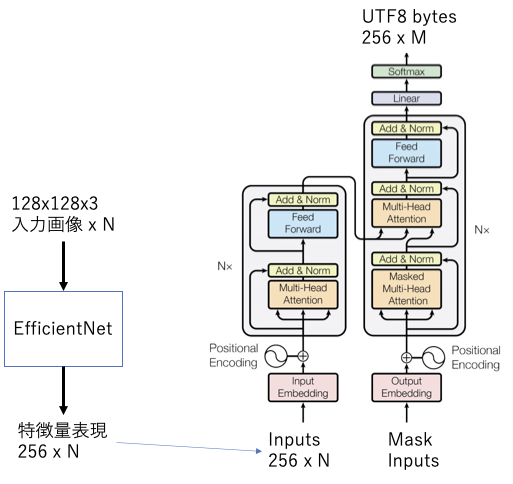
処理を一括できるとよかったのですが、GPUメモリに載らないので、特徴量変換とTransformerを分けました。
特徴量変換器は任意のものでよいのですが、ここではEfficientNetB2を使用しました。 出力を適当な方法で、256次元にします。
この学習時は、256次元の特徴量をさらに、104と100個の分類ができるようにレイヤーを追加します。 それぞれの出力idを掛けて10400通りの分類出力が得られるようにしました。 これは第4水準の漢字まで全て入れて十分に分類できる数です。
本質的に分離できない、カタカナとひらがなのへなどを除いて、全ての文字が十分識別できるようになるまで学習させます。
特徴量変換器の重みは固定して、Transformerの学習をします。 今回使用したTransformerは、hidden_dim=512, head_num=8, hopping_num=4, dropout_rate=0.1 です。
学習は、Wikipediaと青空文庫からランダムに日本語文章を、Wikipediaからランダムに英語文章を取得して、 最大32文字のランダムな長さで入力して、UTF8バイト列が一致するように学習させました。 また、日付表現、金額表現、数詞表現は、特別にサンプルを作成して入力しています。 全ての漢字をランダムに入力もしています。
もくじへ戻る