
OpenAIのWhisperモデルを使用して、多言語の音声を文字起こしできるアプリです。 端末内で全ての計算を行うため、外部に漏れるおそれがありません。 量子化と重みの枝刈りにより、最も大きい精度が良いlarge-v3モデルが、iPhone15 Proにおいてリアルタイム動作します。
プライバシーポリシーはこちらです。 データーの外部送信はありません。
このソフトはオープンソースです。 https://github.com/lithium0003/whisperapp より確認できます。
事前に変換済みのモデル重みは、 https://huggingface.co/lithium0003/ggml-coreml-whisper に置いてあります。アプリは、この場所からモデルデータをダウンロードしています。
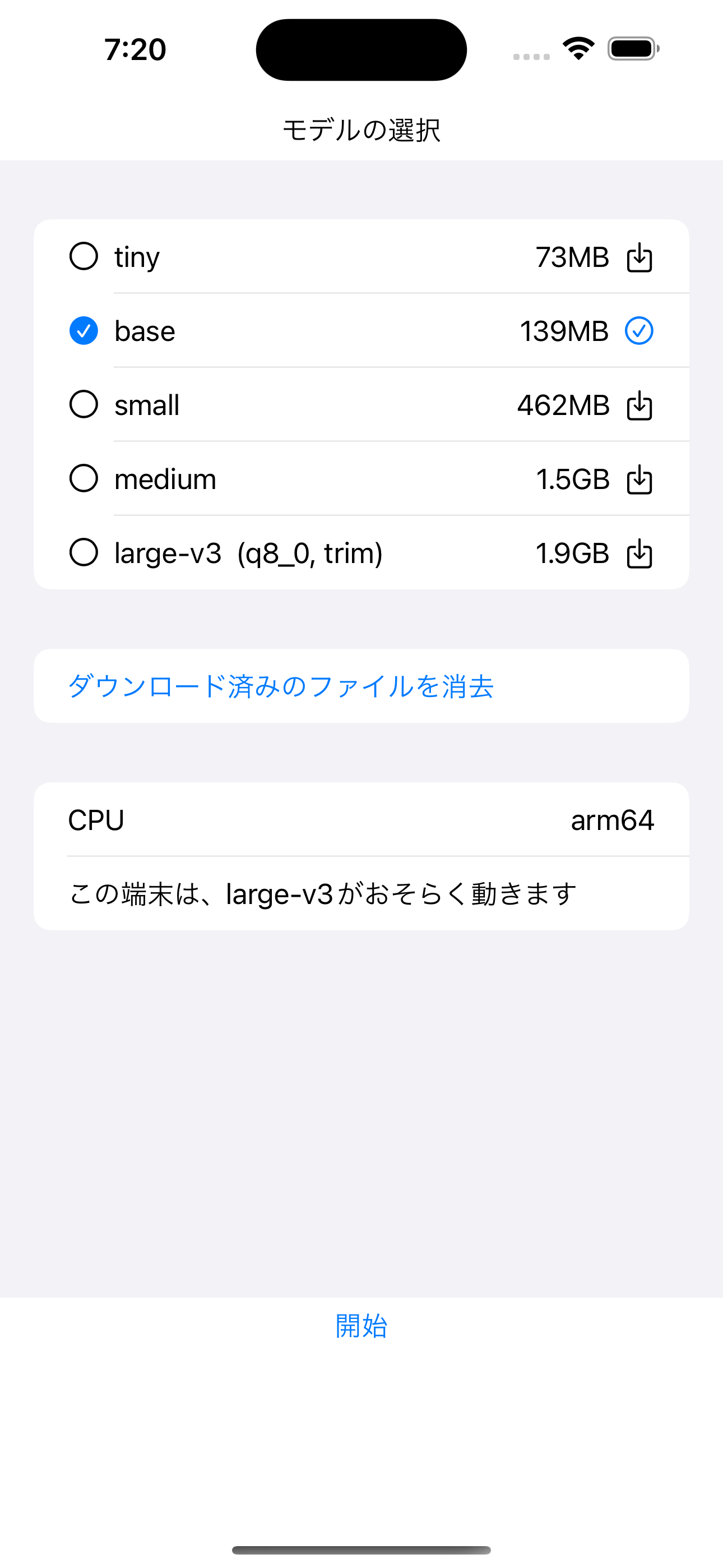


起動すると、マイクの使用許可(初回のみ)が出ますので許可してください。 使用したいモデルのサイズを選んで、開始を押すと、重みファイルのダウンロードが始まり、 終わり次第モデルが読み込まれます。 初回の読み込みは、Neural Engine で実行するための変換処理がある為、数十秒から数分待つ必要があります。 「開始する準備ができました」と表示され、録音ボタンが出現したら準備完了です。
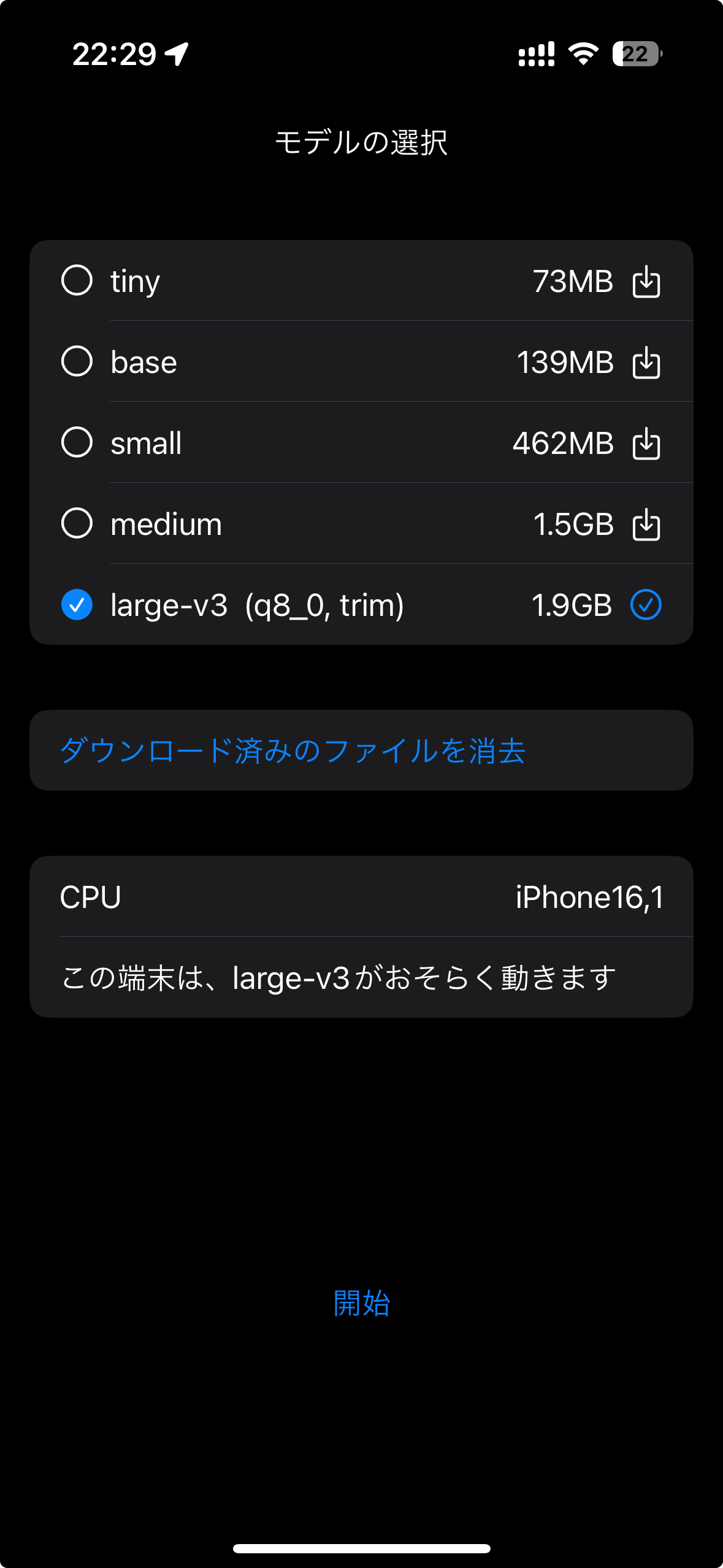
large-v3モデルを使用するには、iPhone15 Proなどの最新のiPhoneや、Apple SiliconのMac、 おそらくM2モデルのiPadなどが必要となります。 それより昔のモデルでは、Neural Engine のコンパイルでシステムがクラッシュする場合があります。 CPUを自動判定して、たぶん大丈夫であると思われる端末には実行できそうと表示されます。

録音ボタンを押すと、音声認識が始まります。 右下のスライダーで、無音とみなす閾値を調整することができます。 無音のしきい値は緑色のバーの長さで表示されています。


音声の大きさは、緑のバーの上のバーで表示され、灰色のバーで無音状態となっているときは 無音しきい値を超えておらず無視されています。 赤色に変化して、検出有効と表示されていると有効な音声入力となっています。
目次に戻る