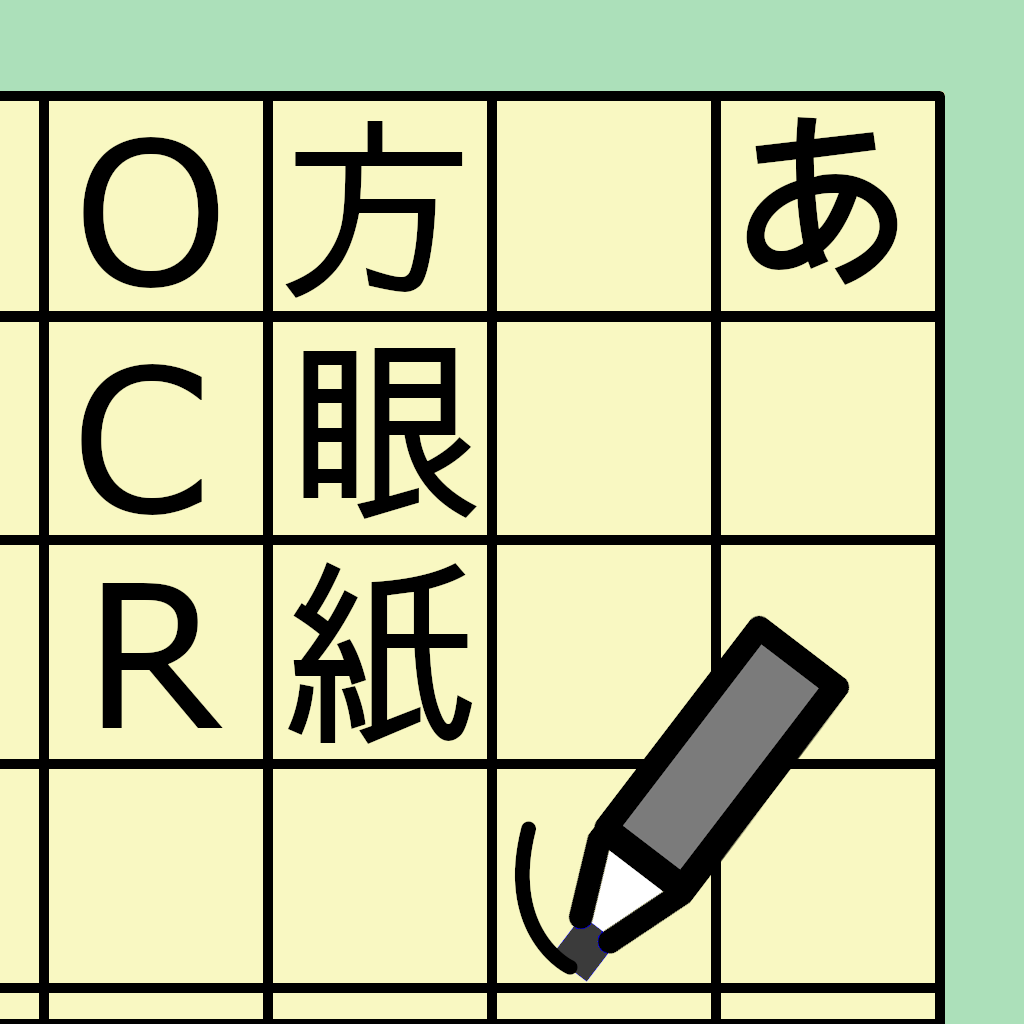
このソフトは、方眼紙に書いた文字を機械学習モデルを用いて端末内の処理のみでテキストにします。
EfficientNetB2 + Transformer の機械学習モデルを用いて、入力された文字の画像の連続から、UTF8エンコードされた文字列を生成します。
EfficientNetは、画像認識に用いられるモデルで、パラメータの最適化を行い少ないパラメータで効率がよいとされています。 Transformerは自然言語の翻訳に用いられることが多い、Attention機構を用いたモデルです。Encoder部とDecoder部からなり、Encoder部に翻訳元の言語の単語列を入力し、Self-Attention機構を用いたモデルで内部表現にします。Decoder部に、スタートとなる単語列を入力し、内部表現とのSourceTarget-Attention機構を用いたモデルで、翻訳先の単語列を生成します。
このアプリに使用したモデルは、手書き文字画像を128x128のカラー画像とし、EfficientNetB2をベースとしたモデルに入力し、256次元の表現に変換します。 256次元 x N文字の入力特徴量を、Transformerの翻訳元言語だと考え、翻訳先を1byteずつのUTF8文字列と考えて生成します。1byteは256個ですので、256個の単語の列として構成された言語だと考えると言うことです。 推論時は、Mask-Predict で提案された、並列に推論させる方法で高速化しています。通常のTransformerは、スタート文字から始めて、終端文字が出現するまで自己回帰により1文字ずつ推論させます。32文字のUTF8表現は最大128byteになり、iPad上の推論速度が数十秒かかってしまうので、精度は落ちますが高速化を図りました。 Mask-Predictの方法は、最初にLengthトークンを翻訳させ、文字長を推論させます。 L=4の候補から、それぞれの文字長のMaskトークンを作成し、本推論の入力とします。このループをT=4回繰り返し、繰り返し毎に推論された信頼度pの上位t/Tの単語を正しいものとし、残りをMaskトークンに置き換えて、次の推論の入力とします。 こうすることで、信頼度の高い単語周りの、自信の無い単語を再度推論させることができます。
ソースコードはgithubで公開しています。https://github.com/lithium0003/TextOCR


格子状のマス目に、手書きで文字を書き、認識開始ボタンを押すと、推論結果が表示されます。できるだけ綺麗に書くと認識が正しくなります。
目次に戻る